Use Cases
MobiSpaces

Figure 2.1.1: MobiSpaces Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| ML-Ops | 1 Sept 2022 | 31 Aug 2025 | 412500,00 € | x |
Table 2.1.1: MobiSpaces Project Info
Partners

Figure 2.1.2: MobiSpaces Partners Logos 01
Overview
MobiSpaces is an end-to-end mobility-aware and mobility-optimized data governance platform based on mobility analytics for efficient, reliable, secure, fair and trustworthy data processing.
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Atos Spain SA | ATOS | Spain |
| Robert Bosch GMBH | BOSCH | Germany |
| Siemens SRL | SIEM | Romania |
| Frequentis AG | FREQ | Austria |
| Azienda Mobilità e trasporti SpA | AMT | Italy |
| Marintrafik Opereisons Monoprospi Anonymi | MOMA | Greece |
| Etairia Pliroforikis | ||
| Emisia SA-Anonymi Etairia Perivallontikon kai Energiakon Meleton kai Anaptixis | Logismikou | |
| Emisia SA-Anonimi Erairia | EMISIA | Greece |
| OKYS LTD | OKYS | Bulgaria |
| Ubitech Limited | UBIT | Cyprus |
| Leanxcale SL | LEANX | Spain |
| Unparallel Innovation LDA | UIL | Portugal |
| Trust-IT Services SRL | TRUST | Italy |
| COMMPLA SRL | COMMPLA | Italy |
| Geodatastyrelsen | GEODATA | Denmark |
| Digital Systems 4.0 | DS4 | Bulgaria |
| NET-U Consutlant LTD | NET-U | Cyprus |
| Universal of Piraeus Research Center | UPRC | Greece |
| Universite Libre de Bruxelles | ULB | Belgium |
| Australian Institute of Technology GMBH | AIT | Australia |
| Aalborg Univeristet | AAUN | Denmark |
| White Label Consultancy APS | WLC | Denmark |
| Fujitsu Service GMBH | FSG | Germany |
| Fujitsu Technology Solutions GMBH | FTSG | Germany |
Table 2.1.2: MobiSpaces Partners
The purpose of the application is to address the problem of bus scheduling. Given a timetable (provided by the municipality of Genoa), it aims to assign a series of bus trips to a specific bus, optimizing battery usage, depot charging times, and overall fleet deployment.
Subsequently, it seeks to transform the maintenance process, currently performed traditionally, into a modern process with an approach based on automatic data learning.
Finally, it aims to measure the degradation of bus battery performance over time, predict their useful life, and anticipate details regarding their maintenance.
Figure 2.1.3: MobiSpaces Partners Logos 02
Zooming into project
MobiSpaces aims to address the complex challenges of managing mobility data by providing a trustworthy and privacy-preserving platform that optimizes data processing for various applications such as intelligent transportation and vessel tracking. Through decentralized processing and validation across multiple use cases, MobiSpaces aims to establish a standard for reliable and sustainable data analytics, fostering growth in the EU digital economy.
Alida in the project
From the management point of view, this work was divided in five different tasks, one for each use case: Task 6.2 (iRoute -- Intelligent Public Transport Routing), Task 6.3 (SmartSense -- Intelligent Infrastructure Traffic Sensing), Task 6.4 (MT
Tracker -- Edge-powered Vessel Tracking), Task 6.5 VesselEdge (Edge Computing Onboard of Moving Vessel) and Task 6.6 (CrowdSeaMapping-- Federated Learning for Enhancing Nautical Charts).
In particular, for iRoute, use case deals with data governance, management and analysis for public transport applications, especially in electric buses field AMT, public transport company in the city of Genova, Italy and leader of iRoute use case, has identified two real scenarios to exploit the research of MobiSpaces, applying it to challenging situations of public transport management, that can be optimized thanks to a right usage of the big amount of data collected everyday by AMT.
The scenarios allow to take advantage of the MobiSpaces outcomes and exploit the mobility-aware data governance framework to drive strategic decisions based on the outcomes of the analytics.
The use case is set in the electric-vehicle environment that is growing in AMT: the e-bus fleet includes more than 100 buses, with the related operational and managerial issues given by the complexity of the electric system, from bus recharging to battery decay.
The first scenario is about predictive maintenance of electric buses and aims to anticipate possible faults, thanks to the machine learning techniques studied in the project. The second scenario deals with battery level management and aims to give an instrument to re-build bus schedules, both real-time and long-term, given predictions on battery duration based on the data analysed and on the expected battery decay.
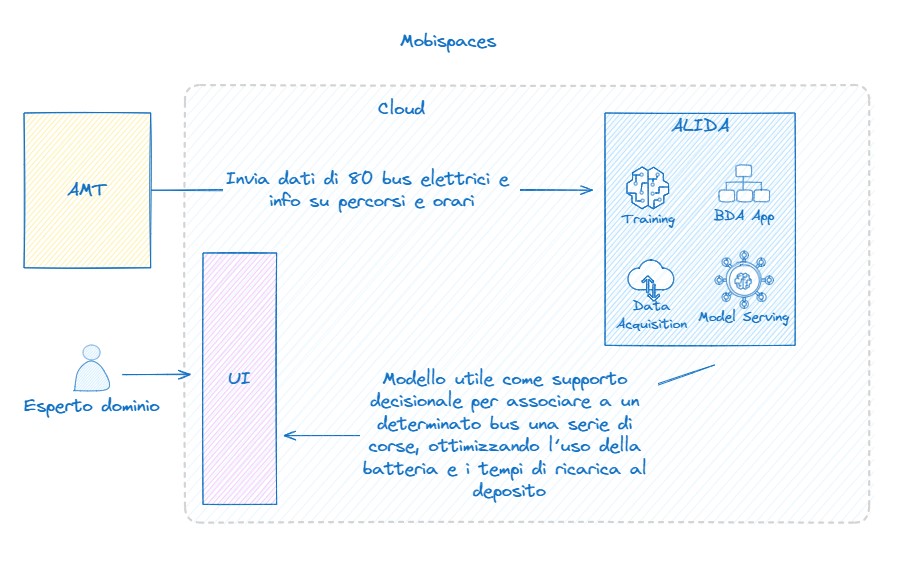
Figure 2.1.4: MobiSpaces Contribution 01
Together with the already quoted machine learning techniques, many MobiSpaces components are working for use case 1, as explained in detail in the paragraphs below. The starting datasets are mostly internal to AMT, and are:
-
AVM (Automatic Vehicle Monitoring) data, that show real-time the positioning of each bus of the fleet and afterwards the trajectory travelled by the bus.
-
GTFS data, that contain the planned transit service in an open de-facto standard used by Public Transport Operators.
-
CanBus data, that collect information about the status of many bus systems including battery level, using FMS standard.
These internal data will be interlinked with external data, relevant for battery level, such as weather data or the elevation and the gradient of the path.
The internal data are usually located and stored on internal servers. A mission of the use case, detailed later in the deliverable, is to create a good, efficient and sustainable data path for the datasets described.
CyberSEAS

Figure 2.2.1: CyberSEAS Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| FML | 1 Octo 2021 | 30 Sept 2024 | €722264,38 | x |
Table 2.1.4: CyberSEAS Project Info
Partners

Figure 2.2.2: CyberSEAS Partners Logo
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Consorzio Interuniversitario Nazionale per l'Informatica | CINI | Italy |
| Airbus Potect GMBH | AIRP | Germany |
| Fraunhofer Gesellschaft zur Fonderung der Angewandten Forschung EV | FGFR | Germany |
| Guardtime | GT | Estonia |
| Ikerlan S. COOP | IKS | Spain |
| Informatika Informacijske Storitve in Inzeniring DD | IIS | Slovenia |
| Rheinisch-Westfaelische Technische Hochschule Aachen | RWTG | Germany |
| Software Imagination &Vision SRL | SIV | Romania |
| Software Quality System SA | SQS | Spain |
| STAM SRL | STAM | Italy |
| Synelixis Lyseis Pliroforikis | SLPA | Greece |
| Automatismou & Tilepikoinonion Anonimi Etairia | ATAE | Greece |
| Wing ict Solutions Technologies Pliroforikis kai Epikoinonion Anonimi Etaireia | WSTP | Greece |
| Ziv Aplicaciones y Tecnologia SL | ZAT | Spain |
| Comune di Berchidda | CDBE | Italy |
| Comune di Benetutti | CDBT | Italy |
| Eles doo Operater Kombiniranega Prenosneg in Distribucijskega Elektroenergetskega Omrezja | EOKP | Slovenia |
| Petrol Slovenska Energetska Druzba dd Ljubljana | PSED | Slovenia |
| Akademska in Raziskovalns Mreza Slovenije | ARMS | Slovenia |
| Hrvatski Operator Prijenosnog Sustava D.D. | HOPS | Croatia |
| Enerim OY | ENER | Finland |
| Elektrilevi OU | ELL | Estonia |
| Compania Nationala de Trasport al Energiei Electrice Transelectrica SA | CNTE | Romania |
| Centrul Roman al Energiei | CRE | Romania |
| Timelex | TML | Belgium |
| Operato DOO | OPER | Slovenia |
Table 2.2.1: CyberSEAS Partners
Overview
The benefits of using Federated Machine Learning (FML) include the ability to train models on distributed data without having to centralize them, ensuring data privacy and reducing the risk of transmitting sensitive information.
Within the CyberSEAS project we worked on a use case in the field of Social Engineering Detection, in particular in training intelligent models to detect fraudulent emails from the analysis of its text.
The FML therefore allowed us to create a text classification model for emails in a collaborative and secure way, without compromising the confidentiality of the personal data contained in the emails themselves.
Zooming into Project
The move towards more agile, connected, intelligent and data-driven energy systems, and their interconnection with our day-to-day lives, means that there is a major increase in cyber exposure of energy systems leading to major safety and privacy incidents.
The EU-funded CyberSEAS project improves the resilience of energy supply chains by protecting them from disruptions generated by complex attack scenarios.
CyberSEAS delivers an open and extendable ecosystem of 30 customisable security solutions providing effective support for key activities, such as risk assessment; interaction with end devices; secure development and deployment; real-time security monitoring; skills improvement and awareness; and certification, governance and cooperation. CyberSEAS solutions will be validated through experimental campaigns consisting of numerous attack scenarios.
Alida in the Project
The adopted solution in CyberSEAS is the synergistic use of ALIDA tool, in pair with SED (Social Engineering Detection).
ALIDA (Advanced Learning and Integration for Data Analysis) is a platform designed for federated machine learning and big data analytics. It facilitates secure, scalable, and privacy-preserving machine learning across distributed datasets. The platform supports various machine learning frameworks and provides tools for developing, registering, and managing BDA services.
SED (Social Engineering Detection): The SED tool focuses on detecting social engineering and phishing attempts through comprehensive analysis of email headers, body content, and attachments.
Most existing FML-enabled platforms support only a few open-source frameworks/libraries available to support the development/integration of FML-based algorithms. On the other hand, the solution integrated within the ALIDA asset wants to be able to support as many existing libraries and frameworks as possible, and in such a way as to be able to perform its own federation tasks quickly, thanks also to the support of a cloud-side graphical interface, and by exploiting/re-utilizing the algorithms made and already available within the ALIDA catalogue.
ALIDA leverages FLOWER (Federated Learning Over Wireless Networks) [4] federated learning framework because of its flexibility, customizability, interoperability, and easiness of use. Its design integrates workflows independent of the ML/DL framework (PyTorch, TensorFlow, etc.) with minimum performance overhead. It supports a wide range of machine learning algorithms, including deep learning, reinforcement learning and classical machine learning. It also includes model aggregation and fault tolerance, which are critical components of any federated learning system. Flower allows building scalable federated learning systems that can be deployed on a range of devices, including mobile phones, edge devices, and cloud servers.
The CyberSEAS federated and self-sovereign data analytics infrastructure has been built starting from the ALIDA platform, one of the tools made available in the CyberSEAS toolset. ALIDA (https://home.alidalab.it/) is a Data Science (DS) and ML platform based on advanced frameworks and open-source technologies for design, deployment, execution and monitoring of both stream and batch Big Data Analytics (BDA) workflows.
ALIDA is cloud-native, so it is able to scale computing and storage resources thanks to a pipeline orchestration engine that leverages the capabilities of Kubernetes for cloud resource management. ALIDA provides an extensible catalogue of BDA services (the building blocks of the BDA Application) which covers all phases, from ingestion to preparation, to ML analysis and for data publishing.
The reference framework used to enable FML between multiple client nodes and an aggregator node is Flower, a unified approach to federated learning, analytics, and evaluation. As shown in the next Figure 2.2.3: FML Architecture Flow in ALIDA platform, ALIDA allows federated model training, so that users can train models without the need to expose data.
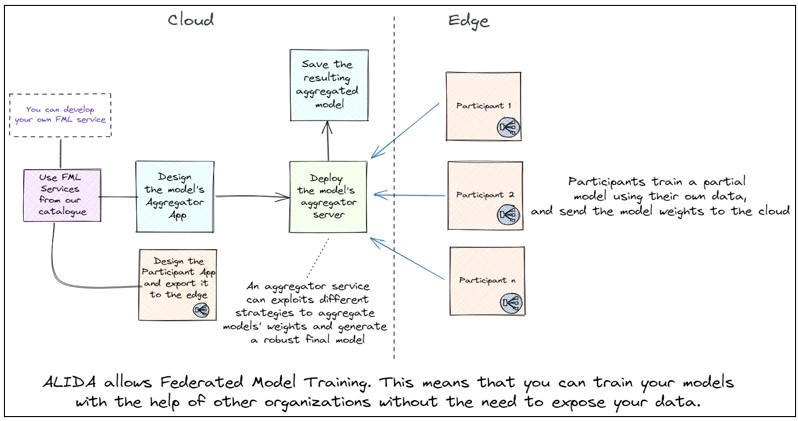
Figure 2.2.3: FML Architecture Flow in ALIDA platform
Among the few open-source technologies that enable FML, Flower has been chosen for the following features:
-
Scalability: it was built to enable real-world systems with many clients
-
ML Framework Agnostic: it's compatible with most existing and future machine learning frameworks such as PyTorch, Keras, SK-Learn
-
Cloud, Mobile, Edge & Beyond: it enables research on all kinds of servers and devices, including mobile
-
Research to Production: it enables ideas to start as research projects and then gradually move towards production deployment with low engineering effort and proven infrastructure
-
Platform Independent: it's interoperable with different operating systems and hardware platforms to work well in heterogeneous edge device environments
-
Usability: it's easy to get started with code examples for different frameworks.
Starting from the Flower framework, templates have been created for a new pair of BDA services areas for ALIDA platform: FML Aggregator and FML Participant areas, thus based on specific modules for the micro-service to be ALIDA compliant, being able to integrate and use at the same time all the features provided by Flower.
CiTrace

Figure 2.3.1: CiTrace Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| FML | 1 June 2021 | 1 May 2024 | n.a. | n.a. |
Table 2.3.1: CiTrace Project Info
Partners

Figure 2.3.2: CiTrace Partners Logo
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| EHT | EHT | Italy |
| Oranfresh | ORF | Italy |
Table 2.3.2: CiTrace Partners
Overview
The CiTrace project proposes a reinterpretation of the concept of traceability in the Agrifood sector, offering a data-centric solution that views the product as an Information Vector along the entire production chain, from the field to the final consumer.
This Information Vector progressively enriches its informational content by leveraging all available information sources continuously. Applied to the citrus supply chain, the CiTrace solution acts as a concentrator of harmonized information, on which a set of Value-Added Services and specific tools can be built for the different phases of the supply chain, benefiting all involved stakeholders.
Zooming into Project
In the context of an agri-food project, Alida will be used to provide:
The Flexible and Optimal Pricing Strategy service is calculated considering three main indicators: production cost, selling price, and brand reputation. Once all necessary information and values are obtained, the result of executing the pipeline is a dataset that indicates the optimal and flexible pricing strategy.
Evaluating the shelf life of products along the supply chain through mathematical models and Machine Learning algorithms, aiming to obtain a trained model representing the added value of Dynamic Shelf-Life Assessment.
In defining the optimal distribution strategy, a fundamental role is played by analyzing data collected along the entire supply chain. This service is obtained by calculating and combining three indices: market penetration rate, inventory turnover, and order fulfilment. The Optimal Distribution Strategy model will be the result of training a Machine Learning algorithm based on these data.
BD4NRG

Figure 2.4.1: BD4NRG Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| ML-OPS | 1 Janu 2021 | 1 Dece 2023 | € 833 000,00 | n.a. |
Table 2.4.3: BD4NRG Project Info
Partners

Figure 2.4.2: BD4NRG Partners Logos
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Ethnicon Metsovion Polytechnion | EMP | Greece |
| Rheinisch-Westfaelische Technische Hochschule Aachen | RWTHA | Greece |
| European Dynamics Luxembourg SA | EDL | Luxemburg |
| International Data Spaces EV | IDS | Germany |
| European Network of Transmission System Operators for Electricity Aisbl | ENTSO | Belgium |
| Panepistimio Dytikis Attikis | PDA | Greece |
| Atos Ppain SA | ATOS | Spain |
| Fundacion Cartif | FC | Spain |
| Univerza v Ljubljani | UNIL | Slovenia |
| Enel x srl | ENEL | Italy |
| Rede Electrica Nacional SA | REN | Portugal |
| Centro de Investigacao em Energia Ren - State Grid SA | CIER | Portugal |
| Uninova-Instituto de Desenvolvimento de Novas Tecnologias-Associacao | UNINOVA | Portugal |
| Enercoutim - Associacao Empresarialde Energia Solar de Alcoutim | ENERC | Portugal |
| Fiware Foundation EV | FIWARE | Germany |
| Centrica Business Solution Belgium | CBSB | Belgium |
| Nederlandse Organisatie voor Toegepast Natuurwetenschappelijk Onderzoek TNO | NORNO | Netherlands |
| Asm Terni SPA | ASM | Italy |
| Vides Investiciju Fonds SIA | VIF | Latvia |
| Comsensus, Komunikacije in Senzorika DOO | COMS | Slovenia |
| Holistic Ike | HI | Greece |
| Interuniversitair Micro-Electrinica Centrum | IMEC | Belgium |
| Terrasigna SRL | TER | Romania |
| UBIMET GMBH | UBIMET | Austria |
| Elektro Ljubljana Podjetje Zadistribucijo Elektricne Enerije D.D. | ELPZ | Slovenia |
| Borzen, Operater Trga z Elektriko, D.O.O. | BORZ | Slovenia |
| Ajuantamiento de Sant Cugat del Valles | ASCV | Spain |
| Eles doo Operater Kombiniranega Prenosnega in Distribucijskega Elektroenergetskega Omrezja | EOKP | Slovenia |
| E-LEX - Studio Legale | ELEX | Italy |
| Osmangazi Elektrik Dagitim Anonim Sirketi | OED | Türkiye |
| Veolia Servicios Lecam Sociedad Anonima Unipersonal | VSLSAU | Spain |
| Stichting Egi | SEGI | Netherlands |
| Cintech Solution LTD | CSL | Cyprus |
| Emotion SRL | EMO | Italy |
Table 2.4.4: BD4NRG Partners
Case Overview
BD4NRG envisions to confront big data management challenges for the energy sector, giving a competitive edge to the European stakeholders to improve decision making and at the same time to open new market opportunities.
Zooming into Project
BD4NRG aims to enable an incremental decentralized energy data-driven ecosystem and a collaborative data sovereignty driven ecosystem. The goal is to unlock and exploit the economic potential of big data and give to Energy Sector stakeholders, the opportunity to improve their business operational performance.
To achieve this and to address the emerging challenges in big data management, BD4NRG partners will develop, adapt, deliver and deploy a distributed big data energy analytics framework - BD4NRG Framework, consisting of:
-
Several distributed intelligent collaborative federated nodes, the BD4NRGData Hubs
-
A graphically enriched Open Modular Big Data Analytics Energy Toolbox
-
A scalable big-data energy analytics environment
BD4NRG will combine DLTs/blockchain technologies with edge processing, Federated Machine Learning and Artificial Intelligence, to operate the data-driven energy ecosystem. Also, the project will make extensive adoption of open sources technology components and tools and Open APIs.
The BD4NRG Framework will include 4 horizontal and 1 vertical (cyber security) layer:
Data Governance Layer
A necessary middleware to act as a mediator between data users and data providers who may want to decide case by case whether to disclose their data or not. State of the art solutions to guarantee traceability, provenance tracking and accountability but guaranteeing confidentiality as well.
Scalable Big Data Management & Processing Layer
Smart management and processing of data by an intelligent information broker. The content of multiple data sources, being generated, managed and stored in the data management systems and the data hubs of the different operators and actors by innovative components and technology enablers.
Applications Layer
Analytics-centred applications tailoring power network improved cross-functional decision-making to improve power network reliability, optimize management of flexibility assets, address building-scale energy efficient comfort management and dynamic situated renewable investment risk assessment.
-
Open Modular Smart Grid Big Data Analytics Toolbox: User-friendly with modern vision of the data analytics Toolbox, providing a working space for self-service capabilities that give autonomy to the end-user combining data that come from different sources.
-
Data / Models / Resources Marketplace: A virtual workbench with a variety of assets, including data, third party services, machine learning models, computing resources and storage resources as tradable assets providing off the shelf tools, library of reusable AI-based machine learning models, external off-domain data sets and reusable data-driven analytics applications.
Cyber Security - Data Privacy Layer
A vertical layer to establish user authentication and authorisation to secure the non-open data of the transaction as well as to comply with the EC regulation on Data Protection
Alida in the Project
BD4NRG aims to develop data analytics services capable to analyse data in a seamless and holistic fashion, across multiple data sources. Among the existing efforts analysed, ALIDA BDA platform has been selected as a starting point for the BD4NRG Analytics Toolbox and it will be extended and validated in the energy domain, according to the needs that emerged in the requirements elicitation phase of the project. ALIDA embraces the paradigm of BDA-as-a-service (BDAaaS). Besides relevant cost savings, the provision of Big Data analytical capabilities using the cloud delivery model could ease the adoption of the toolbox and could simplify useful insights with different kinds of competitive advantage. BDAaaS consists of as a set of automatic tools and methodologies that allows users lacking Big Data expertise to manage BDA and deploy big data pipeline applications ready-to-be-executed addressing their goals at edge/fog/cloud nodes.
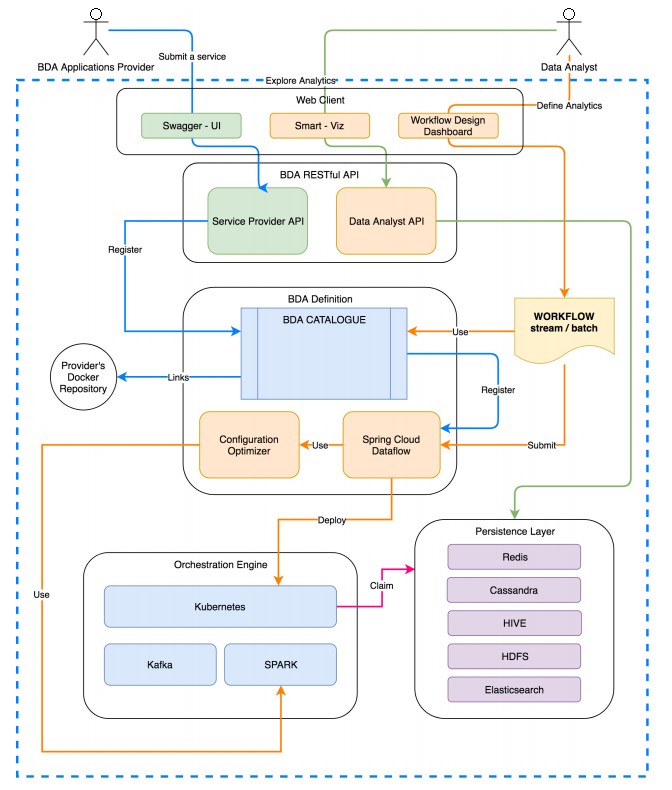
Figure 2.4.3
Figure 2.4.3: ALIDA general architecture for BD4NRG
The ALIDA platform supports full orchestration of BDA application workflows and allows for composition, deployment and execution of workflows (either batch or stream) of BDA applications. Figure 2.4.3 describes the ALIDA general architecture.
SCREAM

Figure 2.4.3
Figure 2.5.1: SCREAM Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| CLOUD-EDGE | 1 July 2020 | 30 June 2023 | n.a. | n.a. |
Table 2.5.5: SCREAM Project Info
Partners

Figure 2.5.2: SCREAM Partners Logo
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Eka Srl | EKA | Italy |
| IPREL Progetti Srl | IPREL | Italy |
Table 2.5.6: SCREAM Partners
Case Overview
The SCREAM project proposes to study, define, design and implement an integrated, modular, flexible and adaptable platform for building dedicated solutions for the remote and optimised monitoring, maintenance and management of machines (Monitoring and Control - M&C) and production equipment (e.g. to predict equipment failures and determine solutions before they occur).
The platform will allow machine problems to be diagnosed (or predicted) and resolved via secure remote access, without the need for an on-site visit.
An open-source GUI for data visualization and exploration was made available on the cloud to consult both the stored historical data and the predictions obtained from the ML models trained on the consumption of the cutting blade and number of cuts; other ML/DL models for predictive maintenance and decision support were exported and used within applications run on the Sofidel company's own machines, applied to real-time data.
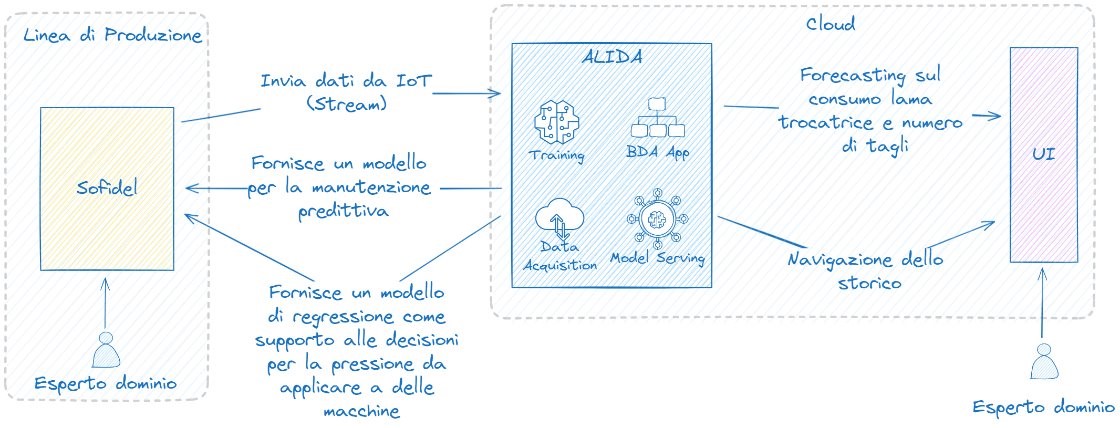
Figure 2.5.3: SCREAM Contribution 01
Zooming into Project
The solutions proposed in the project will be based on Big Data and Artificial Intelligence and will consider the specific characteristics, peculiarities, needs and requirements of the production environment and the organisations using the production equipment and machines. Furthermore, special attention will be given to the specific business relationship that exists between the manufacturer/supplier and the various users (goods producing industries).
Engineering is the Project Coordinator and is responsible for all activities linked to the definition of the SCREAM Framework. Engineering is also working on Big Data Infrastructure for remote and secure "M&C" systems, aiming to define the infrastructure for Industrial Big Data Analytics based on a hybrid edge-cloud model and a complete toolkit of algorithms and analysis techniques to support machine analyses. Moreover Engineering takes care of the design of application services for the remote "M&C" systems of production machinery, with the aim of offering advanced services to support decision making.
Alida in the Project
In the example, the company Sofidel (producer of paper for hygienic and domestic use) sends IoT data in streaming to ALIDA through an asynchronous MQTT messaging protocol. This data includes information from machinery (embosser, rewinder, cutter blade, unwinder) for paper production.
In ALIDA, both BDA App streaming for the data acquisition and data preparation, and batch for pre-process and generate ML/DL models based on data stored within distributed data storage.
Infinitech

Figure 2.6.1: Infinitech Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| ML-OPS | 1 Octo 2019 | 31 Marc 2023 | n.a. | n.a. |
Table 2.6.7: Infinitech Project Info
Partners

Figure 2.6.2: Infinitech Partners Logo 01
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Atos Spain Sa | ATOS | Spain |
| Ibm Israel - Science And Technology Ltd | IBM | Israel |
| Fujitsu Technology Solution | FUJITSU | France |
| Hewlett Packard Italiana Srl | HP | Italy |
| Singularlogic Anonymi Etaireia Pliroforiakon Systimaton Kai Efarmogonpliroforikis | SAEP | Greece |
| Innovation Sprint | IS | Belgium |
| Santander Uk Plc | SAN | United Kindom |
| Sia Spa | SIA | Italy |
| Unicaja Banco Sa | UB | Spain |
| National Bank Of Greece Sa | NBG | Greece |
| Aktif Yatirim Bankasi As | AYB | Türkiye |
| Banka Slovenije | BS | Slovenia |
| Banking & Payments Federation Ireland Company Limited By Guarantee | BPFI | Ireland |
| Dynamis Ae Genikon Asfaleion | DAGA | Greece |
| Genillard & Co Gmbh | GEN | Germany |
| Jrc Capital Management Consultancy & Research Gmbh | JRC | Germany |
| Prive Services Europe Gmbh | PSE | Austria |
| Crowdpolicy Psifiakes Symmetoxikesypiresies | CPSI | Greece |
| Poste Italiane - Spa | PI | Italy |
| Wenalyze | WEN | Spain |
| Paris Europlace | PE | France |
| Copenhagen Fintech | CF | Denmark |
| Reportbrain Limited | RL | United Kingdom |
| Leanxcale Sl | LEAN | Spain |
| Gioumpitek Meleti Schediasmos Ylopoiisi Kai Polisi Ergon Pliroforikis Etaireia Periorismenis Efthynis | GMSY | Greece |
| Innov-Acts Limited | IAL | Cyprus |
| Unparallel Innovation Lda | UI | Portugal |
| Roessingh Research And Development Bv | RRAD | Netherlands |
| Etam Anonymh Etaireia Symboyleytikon Kai Melethtikon Ypireseion | EAES | Greece |
| Fondazione Bruno Kessler | FBK | Italy |
| University Of Galway | UG | Ireland |
| Uninova-Instituto De Desenvolvimento De Novas Tecnologias-Associacao | UID | Portugal |
| Bogazici Universitesi | BU | Türkiye |
| Institut Jozef Stefan | IJS | Slovenia |
| Edex - Educational Excellence Corporation ltd | EDEX | Cyprus |
| University Of Glasgow | UG | United Kingdom |
| Association O.R.T | ORT | France |
| Fundacion Para La Promocion De La Innovacion Investigacion Y Desarrollo Tecnologico En La Industria De Spain Automocion De Galicia | FPLAPDLI | Spain |
| Fundacion Centro Tecnoloxico De Telecomunicacions De Galicia | FCT | Spain |
| Dwf Germany Rechtsanwaltsgesellschaft Mbh | DWF | Germany |
| Abi Lab-Centro Di Ricerca E Innovazione Per La Banca | ABILAB | Italy |
| Bank Of Cyprus Public Company Ltd | BCP | Cyprus |
| Caixabank Sa | CAIXA | Spain |
| Agricultural Applications Ike | AAI | Greece |
| University Of Piraeus Research Center | UPRC | Greece |
| Assentian Europe Limited | AEL | Ireland |
| Clear Communication Associates Ltd | CCAL | United Kingdom |
| Inneurope Initiative S.L. | IISL | Spain |
| The Governor And Company Of The Bank Of Ireland | BOI | Ireland |
| Traffikanalysis Hub Limited | THL | United Kingdom |
| Nexi Payments Spa | NEXI | Italy |
Table 2.6.8: Infinitech Partners 01
Case Overview
Poste Italiane sends data related to banking transactions to ALIDA, which, through the BDA App, trains a model for outlier classification.
This model is then deployed and used on a graphical user interface (UI) to provide a probability (to a domain expert) that new transactions were fraudulent.
The same interface is also utilized to gather feedback from the domain expert, which is useful for enriching the labelling of data, thus making the model increasingly performing with each training iteration. See Figure 2.6.3: Infinitech Contributions 01
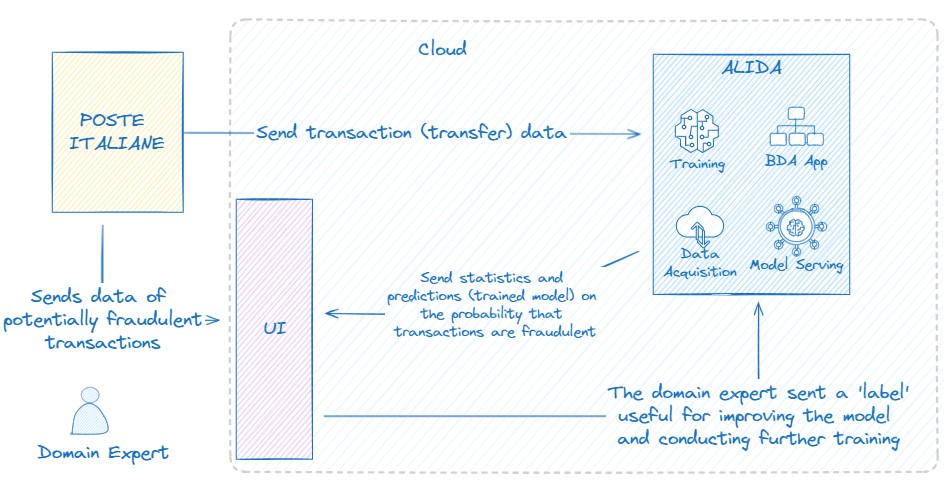
Figure 2.6.3: Infinitech Contributions 01
Zooming into Project
Emerging technologies such as big data, artificial intelligence (AI) and the internet of things (IoT) all have the potential to revolutionise how we live, work and play. But tapping into that potential first requires knowing how to use them -- something that for the financial and insurance industry can be easier said than done.
"Many financial and insurance institutions still face difficulties using big data technology due to complicated regulations and a lack of appropriate test bed resources," says Maurizio Ferraris, innovation manager at GFT Italia.
With the support of the EU-funded INFINITECH project, GFT, together with a consortium of over 40 fintech partners, are working to lower the barriers to datadriven innovation, boost regulatory compliance and stimulate investment.
In a nutshell, ALIDA is a Micro-service based platform for composition, deployment, optimisation, execution and monitoring of pipelines of Big Data Analytics (BDA) services. ALIDA is a result of previous research activities developed by ENG. Currently, it is a work in progress. ALIDA offers a catalogue of BDA services (ingestion, preparation, analysis, visualization): user designs his own (stream/batch) pipeline by choosing the BDA services from it, indicates which Big Data set he wants to process, launches and monitors the execution of the pipeline and personalizes the results visualization by choosing from a set of available graphs, all this without worrying about having software developer skills or particular knowledge on big data technologies. This service is registered in ALIDA catalogue as Spring Boot Application containing the python code and its dependencies. After implementing the algorithm using Pyspark, creating the Dockerfile and pushing the new image inside a repository, this microservice is registered into the ALIDA catalogue through the GUI. Source: https://home.alidalab.it/
ALIDA asset is a microservice based platform for data management and composition, deployment, optimisation, execution and monitoring of big data analytics data workflow (covering ingestion, preparation, analysis and visualization), which has been developed by ENG in previous and ongoing research activities. The main functionalities of ALIDA are:
-
Streaming and Batch data workflow processing
-
Catalogue of Big Data Analytics (BDA) services (covering ingestion, prepara-tion analysis, visualization) for various data analytics scenarios
-
Graphical editor for building data workflow
-
Data pipeline deployment by means of modern resource orchestrators such as Kubernetes
-
Workflow execution monitoring
-
Data visualization customization through a set of graphs and query editor
-
Graphical User Interface to easily create and redistribute new custom BDAservices.
ALIDA presents a microservice architecture, where microservices are deployed in containers, whose management is largely simplified by Kubernetes, a container orchestrator which automates the deployment, management, scaling, and networking of containers.
Basically, Figure 2.6.4: Infinitech Contribution 02 shows three flows: service registration (blue flow), workflow design and execution (red flow) and visualization (orange flow).
The key flow is the workflow design and execution: by means of the GUI user designs a workflow and executes it. In this case, the core components of ALIDA submit the request of execution and deployment of the workflow to the candidate orchestrator. Currently just Spring Cloud Data Flow 8 is adopted as pipeline orchestrator in ALIDA.
Spring Cloud Data Flow (SCDF) is a Microservice based Streaming and Batch data processor that can make use of a variety of container orchestrators. In the ALIDA platform, the SCDF engine instance uses an implementation of the Spring Cloud Deployer for Kubernetes. Then, Kubernetes uses the computation resources available into the platform and the persistence layer to manage data storage and workloads.
The platform currently supports several frameworks such as Spark, H2O, Flink, mainly used for BDA service development and registration. Other frameworks may be deployed, and relevant machine learning libraries available for Python can be used. It is worth to notice that BDA services may or may not be implemented working on these frameworks. The only requirement that the BDA services must match is that they have to be implemented as a spring boot application shipped within a docker image that can optionally contain a python application.
In ALIDA, most of the BDA services developed are based on Spark, so they are able to process a large volume of data, in a distributed environment. Spark is used for both batch and streaming applications thanks to Spark Streaming.
Regarding the persistence layer, Hive and Redis play several roles. Hive is used both to access the data resulting from the execution of the workflows through the visualization component, and to ensure that SPARK can write and read the datasets stored into HDFS.
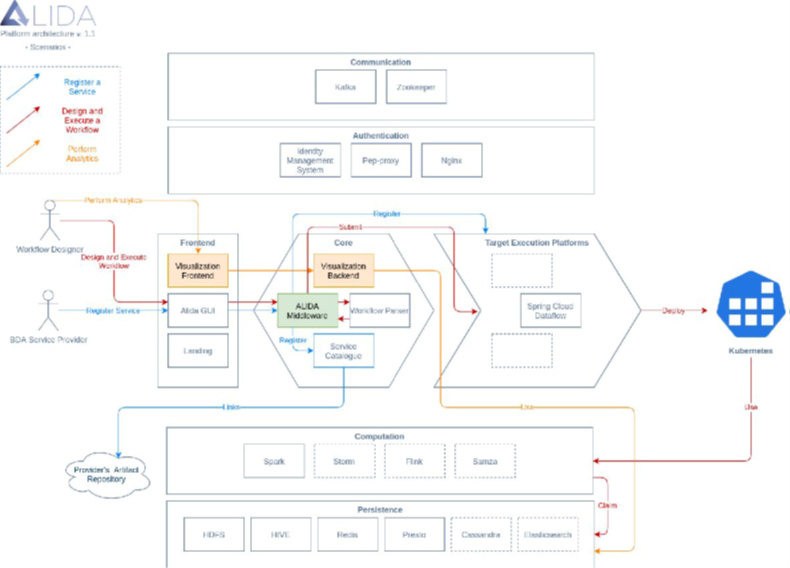
Figure 2.6.4: Infinitech Contribution 02
Redis is used by ALIDA to store some properties related to the platform and to serve the visualization component with the aim to create graphs and visualizations with real time updating capabilities. Last but not least, Kafka is adopted on various fronts: the platform, the core component of ALIDA, uses it to transmit and update the properties during the workflow execution phases. SCDF itself exploits it in the management of streams pipelines. ALIDA is cloud native software, this means that it can be seamlessly deployed both in an on-premises environment and on the cloud environments provisioned by the widely known providers such as Microsoft Azure, Amazon AWS and Google Cloud Platform. In the context of the INFINITECH project, ALIDA will be used in Pilot 10 to facilitate the development of real-time BDA service in the context of Cyber-Security for financial transactions.
Alida in the Project
This pilot aims at significantly improving the detection rate of malicious events (i.e., fraud attempts) and enabling the identification of security-related anomalies while they are occurring by the analysis in real-time of the financial transactions of a home and mobile banking system.
This approach thus allows proactive and prompt interventions on potential security threats. More specifically, Pilot 10 is developing a tool based on ML techniques applied to real-time, financial transaction data-streams focused on adaptive detection for malicious transactions leveraging on established big-data analytics' practices.
The analysis of vast amounts of data will help to define relevant cyber-risk rating metrics and allow us to implement adaptive security measures and controls, based on real cyber-security postures.
Current implementation status on Pilot 10 is shown in Figure 2.6.5: Infinitech Contribution 03.
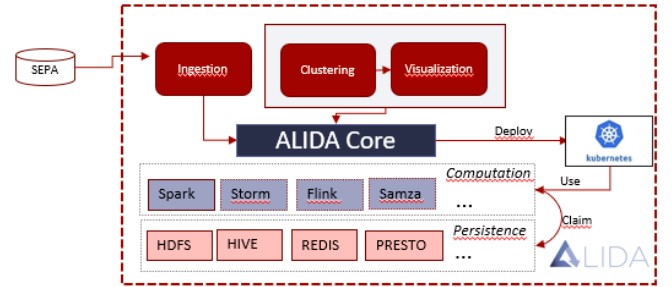
Figure 2.6.5: Infinitech Contribution 03
Poste Italiane create Synthetic and Realistic data set on "Bank Transfer SEPA" transactions that are consistent with the real data present in the data operations environment Figure 2.6.6: Infinitech Contribution 04. These data sets are going to be used by Pilot 10 and, more in concrete, for the first PoC. To develop the services and workflows and ALIDA instance was deployed on ENG premise. As a Preliminary step: a job to transfer synthetic data set on "Bank Transfer SEPA" transactions from an SFTP server to ALIDA HDFS, was designed and it is up and running.
With the data ready to be processed, and using ALIDA, a first Batch processing/workflow has been created. This workflow converts qualitative fields into quantitative one, train a KMeans model and makes the clustering process. The Figure 31:shows developed ALIDA workflow based on three steps (string-indexer, trains the data with a KMeans models and the clustering creation).
After that, the data is grouped and visualized by clusters (Figure 2.6.7: Infinitech Contribution 05).
Here a domain expert has to label which clusters would be suspicious of fraud. After that the Stream processing would start labelling and detecting new incoming data in real time. But this part is not implemented yet.
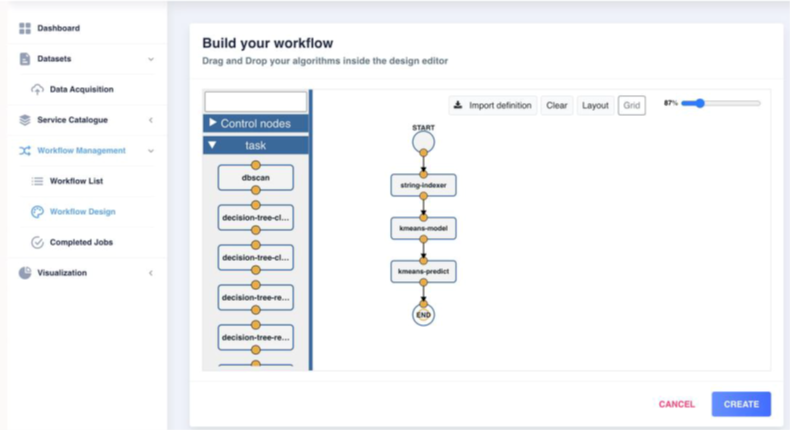
Figure 2.6.6: Infinitech Contribution 04
Figure 2.6.7: Infinitech Contribution 05
OK-INSAID

Figure 2.7.1: OK-INSAID Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| CLOUD-EDGE | 1 Nove 2018 | 31 Marc 2022 | n.a. | n.a. |
Table 2.7.9: OK-INSAID Project Info
Partners

Figure 2.7.2: OK-INSAID Partners Logos
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| EKA S.r.l. | EKA | Italy |
| Università degli Studi di Palermo | UNIPA | Italy |
| Università del Salento | UNISAL | Italy |
| Consiglio Nazionale delle Ricerche | CNR | Italy |
| Cefriel | CEFRIEL | Italy |
| Tera S.r.l. | TERA | Italy |
| Consorzio Calef | CALEF | Italy |
| GE Avio S.r.l. | GEA | Italy |
| SACMI | SACMI | Italy |
Table 2.7.10: OK-INSAID Partners
Case Overview
In this case, the SACMI company that create ceramic slabs sends data to ALIDA in streaming. These data include information about the composition used for the creation of slabs and the results obtained about the quality of the stubs produced. ALIDA, through a streaming BDA App (1), processes, cleans, and stores such data in a distributed store, fundamental for Big Data management.
In a later time, another BDA App batch (2) deals with training of a model based on collected data. An application puts on the edge (Prediction), near the data production site, downloads from ALIDA the model of the produced ML.
This model guides company operators to the composition of the procedure, based on input parameters.
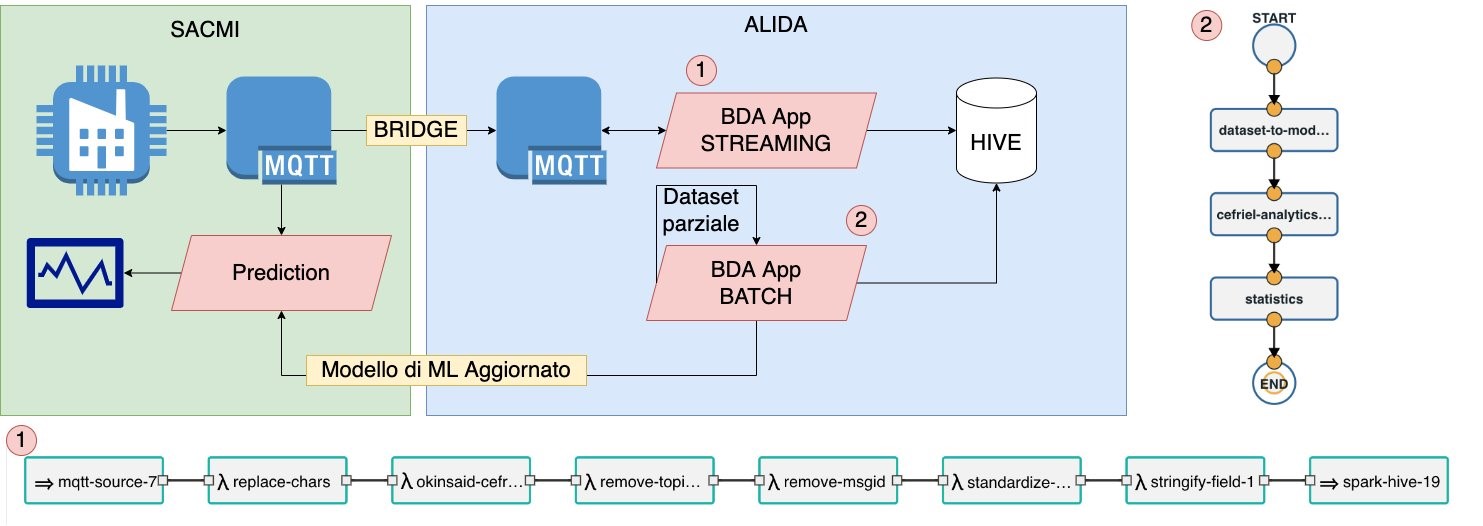
Figure 2.7.3: OK-INSAID Contribution 01
Zooming into Project
One of the most widely adopted quality management strategies today is Zero Defect Manufacturing (ZDM), a new paradigm aimed at surpassing traditional Six Sigma approaches through knowledge management, supported by new methodologies, technologies, and integrated tools for maintenance, quality control, and production logistics.
The general functional requirements of zero-defect manufacturing can be summarized as a system with the following capabilities:
-
Data collection via smart sensors,
-
Automatic signal processing, filtering, and feature extraction,
-
Data mining and knowledge discovery for diagnosis and prognosis,
-
Providing clear and concise information and advice on defects to the user,
-
Self-adaptation and optimization control.
ZDM Monitoring systems highlight that, in order to achieve zero defect manufacturing, new cost-effective tools for monitoring and optimizing quality with multiple and autocorrelated data should be developed.
Therefore, it is necessary to manage processes in real-time based on inputs derived from simulation models to provide a clear and detailed understanding of the entire process and detect all possible causes of defects.
To achieve such digital representations, it is necessary to build a detailed and high-precision model capable of providing various options for identifying optimal product or process parameters.
The suggestion is to adopt Digital Twin technology during the production phase to optimize production planning and process control.
In SACMI's production, the main components identified to better define an investigation in this regard concern porosity and the percentage of average penetration in the welding process.
The algorithms developed to predict the percentage values of penetration and porosity in laser welding have been uploaded to the online platform provided by the project, using the Docker system.
Alida in the Project
The entire predictive analysis pipeline, as designed, implemented, and extensively documented in previous project reports, consists of five fundamental steps (pipeline steps, abbreviated as PS):
-
Pre-processing of datasets, consisting of temporal reordering, cleaning, normalization, splitting into train/validation/test, and final saving of the divided files. [PS1]
-
Model training, exploring different training configurations (e.g., referring to model hyperparameters such as learning rate or the number of training epochs, among others, or the type of training); finally, saving the weights of the trained model. [PS2]
-
Validation of model performance, with the objective of selecting the best configuration based on calculated values for specific accuracy metrics, such as the well-known precision and recall; finally, saving the best parameters. [PS3]
-
Testing model performance, to evaluate the quality of predictions when they are made on new and unseen data, but whose true value is known (i.e., the true welding quality). [PS4]
-
Final prediction on completely new data that, according to what emerged during the project, are provided by the predictive models trained and tested by other partners. [PS5]
Services and Application
The Alida Cloud microservices platform operates on two fundamental components, namely "services" and "applications."
Specifically, one or many services constitute an application. The end user is responsible for launching an application, while the services represent something abstract and internal to the application itself.
In this context, the 5 PS were transferred and implemented as Python scripts within services. To achieve this, the PS were first grouped into:
-
Dataset Preparation + Model Training + Validation [PS1] + [PS2] + [PS3] we could call it as S1;
-
Model Testing [PS4] we could call it as S2;
-
Prediction on New Data [PS5] we could call it as S3.
The three services implemented on the Alida microservices platform were transformed into Docker images to make them portable and host them on the popular Docker image hosting platform known as DockerHub. Indeed, to create a new service on the Alida Cloud platform, a JSON file containing all the characteristics and metadata of the service, including the reference to the Docker image uploaded on DockerHub, must be created.
Thus, a Python script was implemented and released for the partners involved in predictive analysis through the Alida Cloud platform, designed to generate the JSON configuration file.
Having uploaded the services as Docker images on DockerHub and generated the JSON files containing the metadata for each service, it was possible to create and upload the services on the Alida Cloud platform. They can be found on the platform as:
[S1] poliba-fit-3-0 - Figure 2.7.4: OK-INSAID Contribution 02 shows a screenshot of the parameters required by the service.
[S2] poliba-test-3-0 - Figure 2.7.5: OK-INSAID Contribution 03 shows a screenshot of the parameters required by the service.
[S3] poliba-predict-3-6 - Figure 2.7.6: OK-INSAID Contribution 04 shows a screenshot of the parameters required by the service.
Finally, as indicated previously, the three services were grouped to form two applications (named A1 and A2):
[A1] comprising S1+S2, for pre-processing, training, and testing - Figure 2.7.7: OK-INSAID Contribution 05 shows a screenshot of the execution of application A1.
[A2] comprising S3, consisting of prediction on new data - Figure 2.7.8: OK-INSAID Contribution 06 shows a screenshot of the execution of application A2.
Figure 2.7.4: OK-INSAID Contribution 02
Figure 2.7.5: OK-INSAID Contribution 03
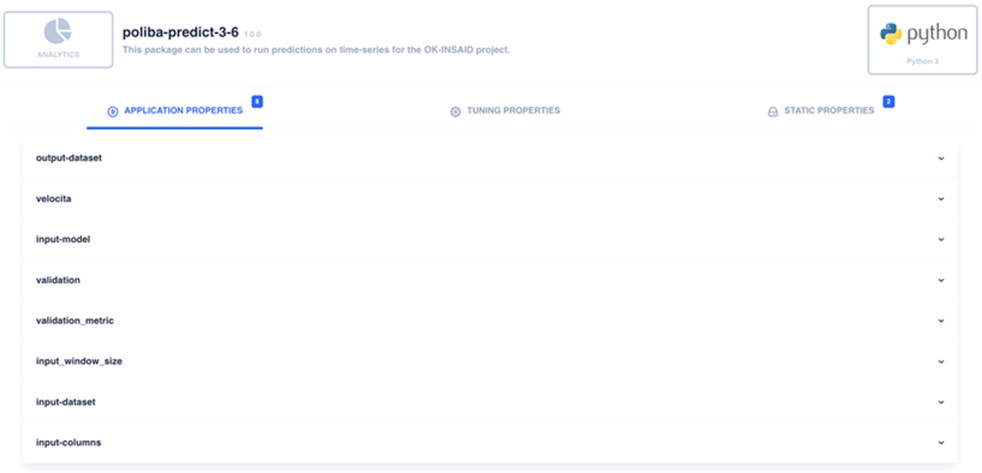
Figure 2.7.6: OK-INSAID Contribution 04
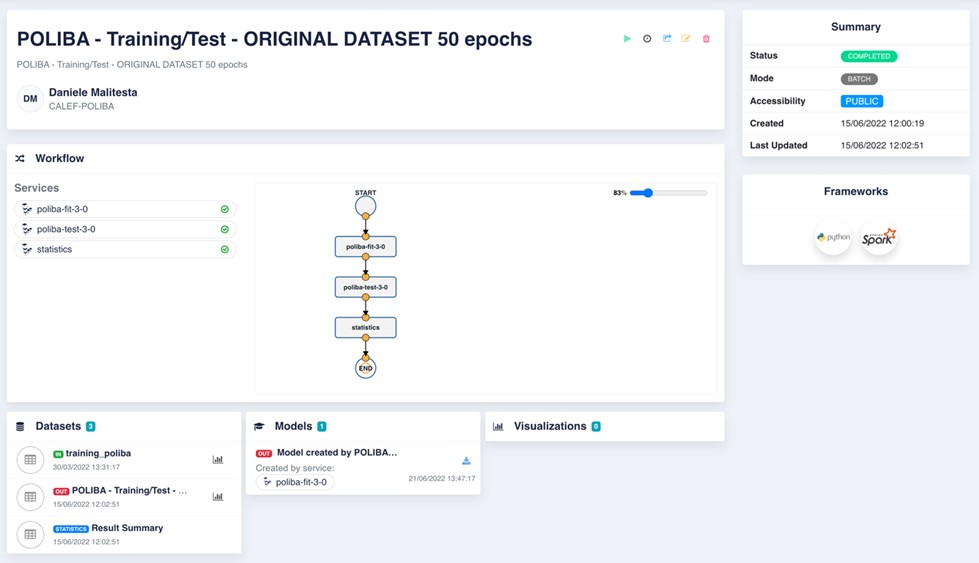
Figure 2.7.7: OK-INSAID Contribution 05
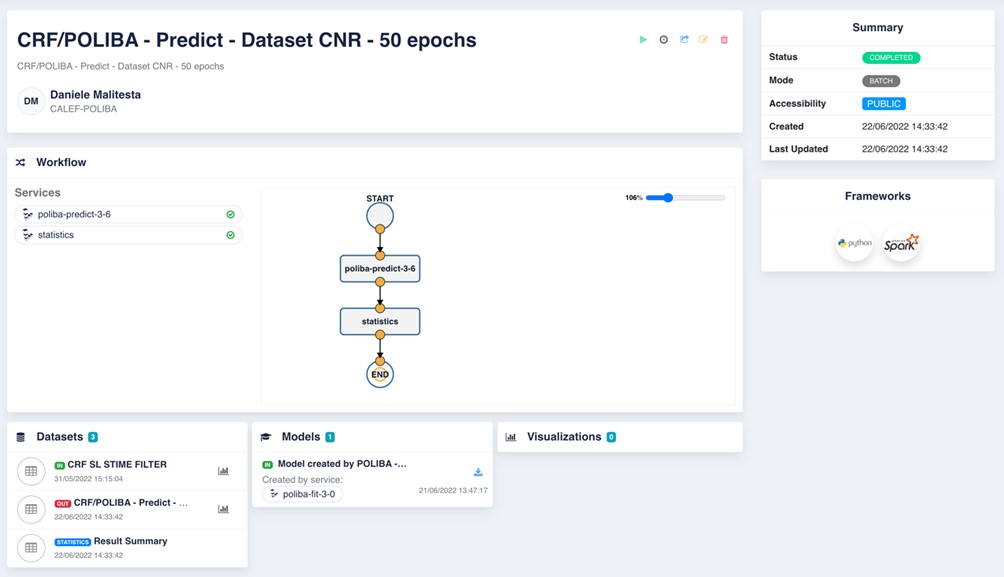
Figure 2.7.8: OK-INSAID Contribution 06
ICARUS

Figure 2.8.1: ICARUS Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| ML-OPS | 1 Janu 2018 | 30 June 2021 | n.a. | n.a. |
Table 2.8.11: ICARUS Project Info
Partners

Figure 2.8.2: ICARUS Partners Logo
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| PACE AEROSPACE ENGINEERING AND INFORMATION TECHNOLOGY GMBH | PACE | Germany |
| SUITE5 DATA INTELLIGENCE SOLUTIONS LIMITED | SUITE5 | Ireland |
| UNIVERSITY OF CYPRUS | UNICYP | Cyprus |
| CINECA CONSORZIO INTERUNIVERSITARIO | CCI | Italy |
| OAG AVIATION WORLDWIDE LIMITED | OAG | UK |
| SINGULARLOGIC ANONYMI ETAIREIA PLIROFORIAKON SYSTIMATON KAI EFARMOGONPLIROFORIKIS | SINGUL | Greece |
| ISTITUTO PER L'INTERSCAMBIO SCIENTIFICO | IIS | Italy |
| CELLOCK LTD | CELLOCK | Cyprus |
| ATHENS INTERNATIONAL AIRPORT S.A. | AIA | Greece |
| SUITE5 DATA INTELLIGENCE SOLUTIONS Ltd | SDIS | Cyprus |
Table 2.8.12: ICARUS Partners
Case Overview
The European aviation industry faces a surge of multi-source and multi-lingual data. The EU-funded ICARUS project will build a novel data value chain in aviation-related sectors aimed at data-driven innovation and collaboration across industry players. Using methods such as big data analytics, deep learning, semantic data enrichment and blockchain-powered data sharing, ICARUS aims to develop a multi-sided platform allowing integration and deep analysis of data for EU-based companies, organisations and scientists. ICARUS will bring together the aerospace, tourism, health, security, transport, retail, weather and public sectors and accelerate their data-driven collaboration.
Zooming into Project
Industries of all types are using the power of big data and analytics to fundamentally transform how they do business. The notable exception is the aviation industry. In fact, there is currently little data diffusion and sharing between the different stakeholders of the aviation-related sectors.
"The European aviation industry needs to leverage the surge of multisource data in order to gain augmented intelligence and open the door to a range of unprecedented services," says Dimitrios Alexandrou, business innovation director at UBITECH, a Greek technology company.
With a focus on building a data value chain, the EU-funded ICARUS (Aviation driven Data Value Chain for Diversified Global and Local Operations) project is helping the aviation industry embrace data-driven innovation. "Using big data analytics, deep learning, data enrichment, and blockchain-powered data sharing, the ICARUS project aims to deliver a unique data and intelligence platform for the aviation industry," adds Alexandrou, who serves as the project coordinator.
A one-stop shop for aviation data and intelligence The objective of the project
is to conceptualise, design and develop the ICARUS platform. When finalised, the platform will enable data exploration, blockchain-empowered sharing, and the brokerage of a large variety of heterogeneous data sources. It will also serve as a one stop shop for aviation data and intelligence -- covering the entire big data lifecycle, from data collection to curation, exploration, integration and analysis.
"The platform will provide users with a deeper understanding of, for example, flight optimisation, pollution awareness, tourism operations, the passenger experience -- even how aviation can cause an epidemic to spread," explains Alexandrou. "As such, it will be an invaluable tool for the aviation industry, aviation-related service providers, and other cross-sectoral stakeholders."
The platform will also serve as a trusted and secure sandbox-style workspace where users can conduct analytical experiments in a safe and confidential closedlab environment. "The ICARUS platform aims to address the security and privacy concerns that have made the aviation industry and related industries reluctant to leverage big data technologies," notes Alexandrou.
According to him, the platform has already received expressions of interest from a number of external stakeholders.
Enabling data-driven innovation and collaboration Despite some delays caused by COVID-19, the ICARUS project succeeded in creating a platform that enables data-driven innovation and collaboration across the aviation sector.
"The ICARUS platform effectively addresses the industry's reluctance to explore, curate, share, trade, integrate and deeply analyse big data in a trusted and fair manner," concludes Alexandrou. "In other words, it provides the big data that will drive the design and implementation of the innovative new services that will disrupt the aviation industry."
The platform will soon be available in beta format. Project researchers are currently exploring the best business plan for bringing the platform to market.
Agritech

Figure 2.9.1: Agritech Project Logo
| Type | Start Date | End Date | ENG Grant Amount | PM |
|---|---|---|---|---|
| ML-OPS | Dec 2021 | May 2024 | n.a. | n.a. |
Table 2.9.13: Agritech Project Info
Partners

Figure 2.9.2: Agritech Partners Logo
| Partner Name | Acronym | Country |
|---|---|---|
| Engineering Ingegneria Informatica S.p.A. | ENG | Italy |
| Consiglio Nazionale delle Ricerche | CNR | Italy |
| Università degli Studi di Bari | UNIBA | Italy |
| Alma Mater Studiorum -- Università di Bologna | UNIBO | Italy |
| Università degli Studi di Milano | UNIMI | Italy |
| Università di Napoli Federico II | UNINA | Italy |
| Università di Padova | UNIPD | Italy |
| Università di Siena | UNISI | Italy |
| Università degli Studi di Torino | UNITO | Italy |
| Centro Euro-Med sui Cambiamenti Climatici | CMCC | Italy |
| Consiglio per la ricerca in agricoltura e l'analisi dell'economia agraria | CREA | Italy |
| New Technologies, Energy and Sustainable Economic Development | ENEA | Italy |
| Fondazione Edmund Mach | FEM | Italy |
| Politecnico di Milano | POLIMI | Italy |
| Politecnico di Torino | POLITO | Italy |
| Scuola Superiore Sant'Anna | SSSA | Italy |
| Università degli Studi della Basilicata | UNIBAS | Italy |
| Università di Bolzano | UNIBZ | Italy |
| Università Campus Bio-Medico di Roma | UCBM | Italy |
| Università Cattolica del Sacro Cuore | UCSC | Italy |
| Università di Catania | UNICT | Italy |
| Università di Foggia | UNIFG | Italy |
| Università di Firenze | UNIFI | Italy |
| Università degli Studi di Genova | UNIGE | Italy |
| Università di Perugia | UNIPG | Italy |
| Università di Pisa | UNIPI | Italy |
| Università di Parma | UNIPR | Italy |
| Università di Reggio Calabria | UNIRC | Italy |
| Sapienza Università di Roma | UNIROMA | Italy |
| Università di Salerno | UNISA | Italy |
| Università di Sassari | UNISS | Italy |
| Università di Udine | UNIUD | Italy |
| Università delle Marche | UNIVPM | Italy |
Table 2.9.14: Agritech Partners
Case Overview
As part of a project within the National Recovery and Resilience Plan (PNRR), there is a need for a use case to train a model that, based on the movements of a cow (monitored through an IoT collar), validates whether the growth occurs outdoors or indoors in a stable.
In addition to creating the ML model and managing its entire lifecycle, ALIDA will also validate satellite data on a blockchain and provide analytical results to a traceability system that will expose the outcome during the scanning phase of the QR code displayed on the finished product.
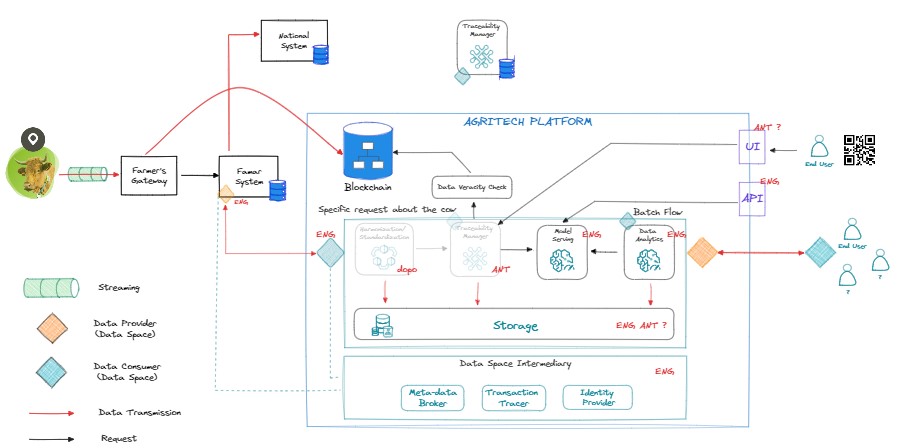
Figure 2.9.3: Agritech Contribution 01
Zooming into Project
In the context of an **Agritech** project, ALIDA can offer tools and methods to efficiently manage and analyze large amounts of agricultural data. Here's how you could use ALIDA in an Agritech project (Figure 2.9.3: Agritech Contribution 01):
- Data Collection and Preprocessing
ALIDA can assist in collecting data from various sources such as IoT sensors, satellite images, and existing databases. Additionally, it provides tools for data preprocessing:
-
Data Cleaning: Removing missing or anomalous data.
-
Data Normalization: Adjusting data to ensure uniformity.
-
Data Integration: Combining data from different sources.
-
Data Analysis
ALIDA offers numerous algorithms for analyzing agricultural data:
-
Statistical Analysis: To understand trends in crop yield data, climate data, etc.
-
Predictive Analysis: Using machine learning models to predict crop yields, plant diseases, and other relevant metrics.
-
Spatial Analysis: For analyzing geographic data, such as land maps and crop distribution.
-
Data Visualization
Effectively visualizing data is crucial for making informed decisions. ALIDA provides tools to create:
-
Interactive Charts: To dynamically explore data.
-
Thematic Maps: To visualize crop distribution, soil moisture, and other geospatial variables.
-
Customized Dashboards: To monitor key metrics in real-time.
-
Process Automation
In the context of Agritech, automation can increase efficiency:
-
Automated Data Collection: Using sensors and drones to collect data automatically.
-
Automated Analysis: Configuring analysis pipelines that automatically perform predictive analyses on new data.
-
Automated Decision-Making: Implementing decision support systems that use analysis results to suggest actions.
-
Specific Applications
-
Crop Monitoring: Using sensor data and satellite images to monitor crop health and identify issues early.
-
Irrigation Management: Analyzing soil moisture data and weather forecasts to optimize water use.
-
Crop Planning: Using predictive models to plan crop rotation and maximize yields.
-
Pest Management: Analyzing data to predict and prevent pest infestations.
-
Alida in the Project
Example of Using ALIDA in an Agritech Project
Imagine an Agritech project aiming to optimize corn production. Here's how you could use ALIDA:
- Data Collection:
Collect data from soil moisture sensors, weather stations, and satellite images.
- Preprocessing:
Clean and normalize the data to ensure quality.
- Predictive Analysis:
Use machine learning algorithms to predict corn yields based on future weather conditions.
- Visualization:
Create maps and charts showing yield predictions and water stress areas.
- Automation:
Implement a system that sends notifications to farmers when it's time to irrigate or fertilize based on predictions and real-time data.
In conclusion, ALIDA can be a powerful tool in an Agritech project, offering advanced functionalities for data collection, analysis, visualization, and automation to improve agricultural efficiency and productivity.