Creazione di un Service
Prima di continuare, se non lo hai già fatto, consulta la definizione di Service
La seguente figura mostra la struttura semplificata di un generico Service:
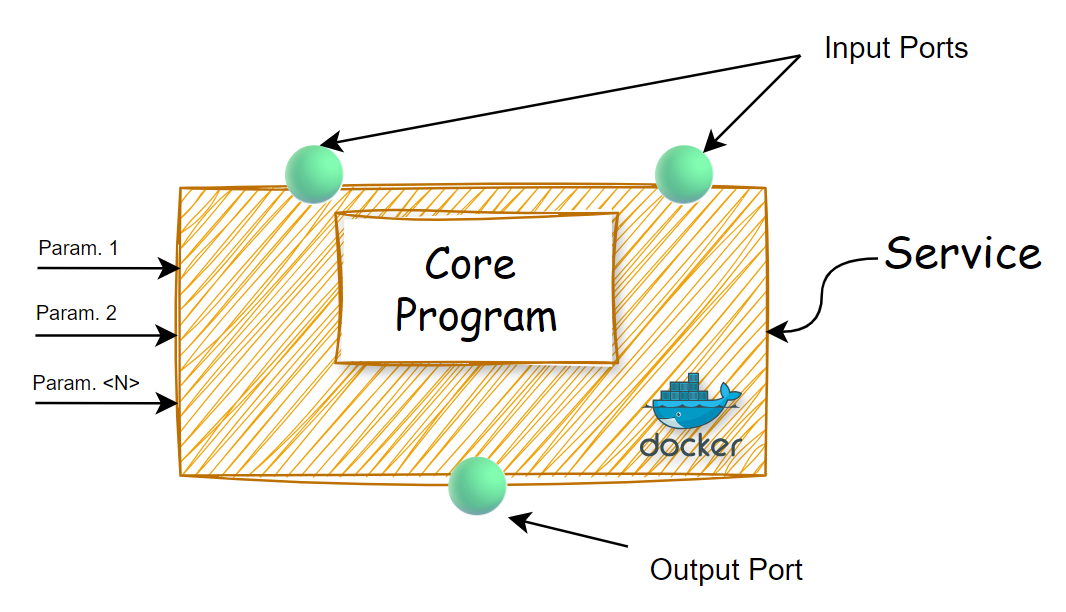
 | Vedremo adesso passo passo come creare un semplice Service da zero fino alla sua registrazione sulla piattaforma.
Esso calcolerà dei semplici indicatori statistici quali media e deviazione standard per un dataset in input, salvando i risultati su di un dataset di output.
| Vedremo adesso passo passo come creare un semplice Service da zero fino alla sua registrazione sulla piattaforma.
Esso calcolerà dei semplici indicatori statistici quali media e deviazione standard per un dataset in input, salvando i risultati su di un dataset di output.
Dataset di input e dataset di output verranno rispettivamente letto e scritto da/su MinIO.
Tale Service avrà quindi:
- Una porta di input di tipo dataset
- Una porta di output di tipo dataset
- Un parametro di esecuzione configurabile
come schematizzato in figura:
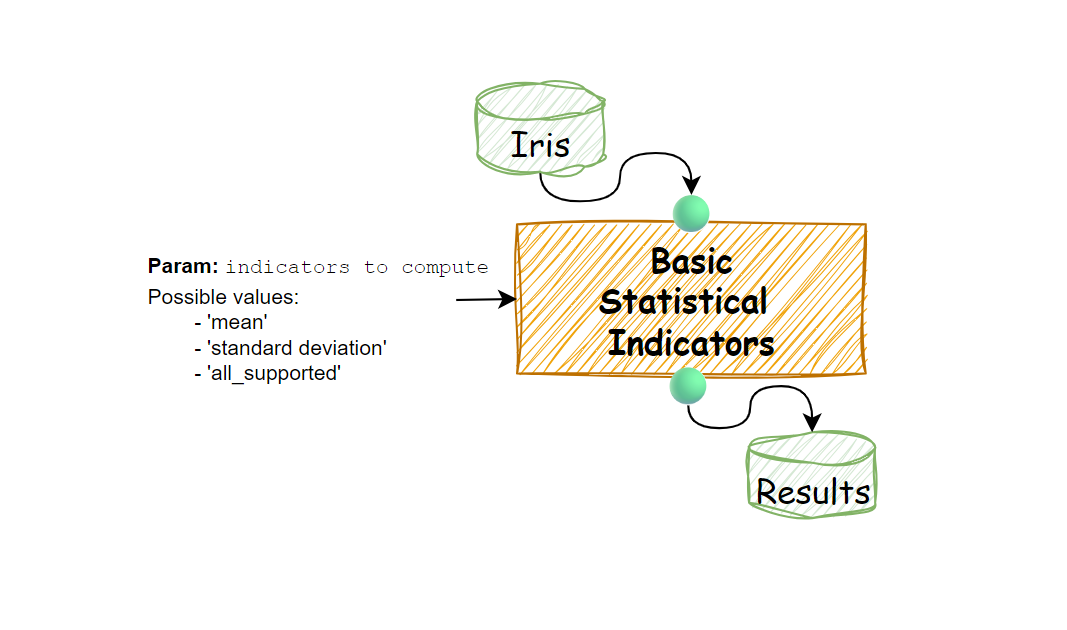
Procediamo quindi:
- Creando il programma nucleo contenente la logica di elaborazione dati
- Buildando un'immagine Docker contenente tale programma
- Caricando l'immagine Docker buildata su di un Docker Registry
- Registrando il programma dockerizzato su ALIDA promuovendolo così a Service
1. Creazione Programma Nucleo
Porta di Input

Predisponiamo la Porta di Input per il nostro Service aggiungendo i seguenti argomenti linea di comando al programma nucleo:
--input-dataset--input-columns--input-dataset.minio_bucket--input-dataset.minIO_URL--input-dataset.minIO_ACCESS_KEY--input-dataset.minIO_SECRET_KEY--input-dataset.minIO_REGION
Ecco il codice di esempio per questi primi argomenti:
Tipo dati argomenti
I valori passati da ALIDA al programma nucleo saranno sempre stringhe o numeri, pertanto occorrerà convertire correttamente il valore al tipo dati desiderato lato codice.
Esempio Python
- Per i booleani utilizzare
str2bool - Per i JSON utilizzare
str2json
import argparse
import pandas as pd
from minio import Minio
import os
parser = argparse.ArgumentParser(description="Basic Statistical Indicators")
# CLI Arguments for the Input dataset port
parser.add_argument('--input-dataset',
dest='input_dataset',
type=str,
required=True
)
parser.add_argument('--input-columns',
dest='input_columns',
type=str,
required=True
)
parser.add_argument('--input-dataset.minio_bucket',
dest='input_dataset_minio_bucket',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_URL',
dest='input_dataset_minio_url',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY',
dest='input_dataset_minio_access_key',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_SECRET_KEY',
dest='input_dataset_minio_secret_key',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_REGION',
dest='input_dataset_region_name',
type=str,
required=False
)
# ... see next step ...
Porta di Output

Predisponiamo ora la Porta di Output per il nostro Service aggiungendo i seguenti argomenti linea di comando al programma nucleo:
--output-dataset--output-dataset.minio_bucket--output-dataset.minIO_URL--output-dataset.minIO_ACCESS_KEY--output-dataset.minIO_SECRET_KEY--output-dataset.minIO_REGION
Ecco il codice di esempio per questi ulteriori argomenti:
# ... omitted - see previous step ...
# CLI Arguments for the Output dataset port
parser.add_argument('--output-dataset',
dest='output_dataset',
type=str,
required=True
)
parser.add_argument('--output-dataset.minio_bucket',
dest='output_dataset_minio_bucket',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_URL',
dest='output_dataset_minio_url',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_ACCESS_KEY',
dest='output_dataset_minio_access_key',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_SECRET_KEY',
dest='output_dataset_minio_secret_key',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_REGION',
dest='output_dataset_region_name',
type=str,
required=False
)
# ... see next step ...
Parametro di esecuzione configurabili dall'utente
Predisponiamo adesso la porta per un parametro di esecuzione ausiliario. Questo permetterà all'utente di specificare l'indicatore statistico da calcolare lato UI.
Aggiungiamo quindi al programma nucleo il seguente argomento linea di comando:
--indicators-to-compute
Ecco il codice di esempio per questo ulteriore argomento:
# ... omitted - see previous steps ...
# CLI Argument for user-configurable execution parameter
parser.add_argument(
'--indicators-to-compute',
dest='indicators_to_compute',
type=str,
required=True,
choices=['mean', 'standard_deviation', 'all_supported']
)
# parse_known_args allows us to ignore the other invocation arguments coming in
# from ALIDA
args, unknowns = parser.parse_known_args()
# ... see next step ...
Ecco quindi schematizzato il nostro programma nucleo con tutti gli argomenti desiderati:
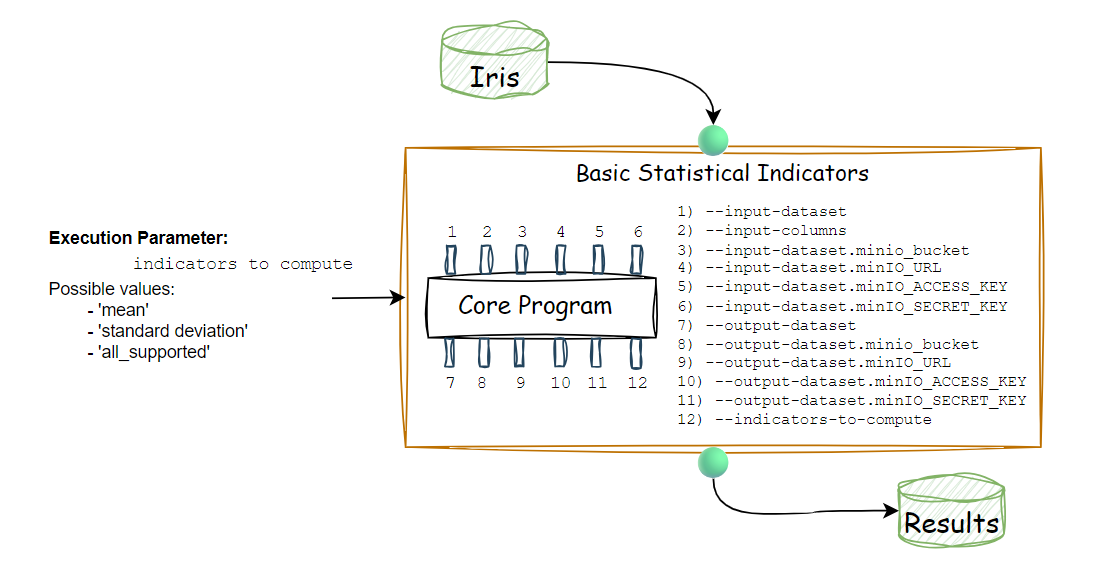
Logica di esecuzione
Aggiunti tutti gli argomenti linea di comando, completiamo il programma con la logica di calcolo degli indicatori statistici. Di seguito il codice completo.
Codice programma nucleo finale
import argparse
import pandas as pd
from minio import Minio
import os
parser = argparse.ArgumentParser(description="Basic Statistical Indicators")
# CLI Arguments for the Input dataset port
parser.add_argument('--input-dataset',
dest='input_dataset',
type=str,
required=True
)
parser.add_argument('--input-columns',
dest='input_columns',
type=str,
required=True
)
parser.add_argument('--input-dataset.minio_bucket',
dest='input_dataset_minio_bucket',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_URL',
dest='input_dataset_minio_url',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY',
dest='input_dataset_minio_access_key',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_SECRET_KEY',
dest='input_dataset_minio_secret_key',
type=str,
required=True
)
parser.add_argument('--input-dataset.minIO_REGION',
dest='input_dataset_region_name',
type=str,
required=False
)
# CLI Arguments for the Output dataset port
parser.add_argument('--output-dataset',
dest='output_dataset',
type=str,
required=True
)
parser.add_argument('--output-dataset.minio_bucket',
dest='output_dataset_minio_bucket',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_URL',
dest='output_dataset_minio_url',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_ACCESS_KEY',
dest='output_dataset_minio_access_key',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_SECRET_KEY',
dest='output_dataset_minio_secret_key',
type=str,
required=True
)
parser.add_argument('--output-dataset.minIO_REGION',
dest='output_dataset_region_name',
type=str,
required=False
)
# CLI Argument for user-configurable execution parameter
parser.add_argument(
'--indicators-to-compute',
dest='indicators_to_compute',
type=str,
required=True,
choices=['mean', 'standard_deviation', 'all_supported']
)
# parse_known_args allows us to ignore the other invocation arguments coming in
# from ALIDA
args, unknowns = parser.parse_known_args()
minio_client = Minio(
args.input_dataset_minio_url.replace("http://", "").replace("https://", ""),
access_key=args.input_dataset_minio_access_key,
secret_key=args.input_dataset_minio_secret_key,
region=args.input_dataset_minio_region,
secure=False
)
objects = list(
minio_client.list_objects(
args.input_dataset_minio_bucket,
prefix=args.input_dataset,
recursive=True
)
)
if not objects:
raise FileNotFoundError("No files found in the given MinIO folder path.")
# Assume only one CSV file
csv_object = objects[0]
csv_filename = os.path.basename(csv_object.object_name)
"""
Since the program is designed to read from MinIO, we need to handle
connection to such an object storage
"""
connection_details = {
'key': args.input_dataset_minio_access_key,
'secret': args.input_dataset_minio_secret_key,
'region': args.input_dataset_minio_region,
'client_kwargs': {
'endpoint_url': f'{args.input_dataset_minio_url}'
}
}
file_path = f"s3://{args.input_dataset_minio_bucket}/{args.input_dataset}/{csv_filename}"
try:
# Read
df = pd.read_csv(file_path, storage_options=connection_details, sep=None, engine='python')
columns = args.input_columns
if columns is not None and columns.strip() != '*':
df_selected = df[[c.strip() for c in columns.split(",")]]
df = df_selected.copy()
numeric_cols_df = df.select_dtypes(include='number')
# Compute
operation = args.indicators_to_compute
if operation == 'mean':
result = numeric_cols_df.mean().to_frame(name='mean').T
result["ResultType"] = "Mean"
elif operation == 'standard_deviation':
result = numeric_cols_df.std().to_frame(name='std').T
result["ResultType"] = "Standard Deviation"
elif operation == 'all_supported':
mean_df = numeric_cols_df.mean().to_frame(name='mean').T
mean_df["ResultType"] = "Mean"
std_df = numeric_cols_df.std().to_frame(name='std').T
std_df["ResultType"] = "Standard Deviation"
result = pd.concat([mean_df, std_df])
else:
raise ValueError(
"Operation must be 'mean', " \
"'standard_deviation', or "
"'all_supported'." \
"")
# Save
csv_filename = 'basic_statistical_indicators_results.csv'
file_path = f"s3://{args.output_dataset_minio_bucket}/{args.output_dataset}/{csv_filename}"
result.to_csv(
file_path,
index=False,
storage_options={
'key': args.output_dataset_minio_access_key,
'secret': args.output_dataset_minio_secret_key,
'region': args.input_dataset_minio_region,
'client_kwargs': {
'endpoint_url': f'{args.output_dataset_minio_url}'
}
}
)
except Exception as e:
print(f"Error: {e}")
2/3. Build e Caricamento Immagine Docker
Procediamo adesso alla creazione dell'immagine Docker incapsulante il programma nucleo.
Nota
In fase di esecuzione del Service, ALIDA istanzierà tale immagine passandole gli argomenti linea di comando valorizzati. Il container Docker istanziato dovrà quindi passare gli argomenti al programma nucleo. Affiché ciò avvenga, l'immagine Docker dovrà avere un opportuno ENTRYPOINT.
Per il nostro Service ecco il Dockerfile (notare l'entrypoint):
FROM python:3.13.7-alpine3.22
RUN pip install pandas==2.3.2 \
minio==7.2.18 \
fsspec==2025.9.0 \
s3fs==2025.9.0
COPY . .
ENTRYPOINT ["python", "main.py", "$@"]
Gli argomenti valorizzati passati da ALIDA al container Docker verranno sostituiti a $@.
Altri linguaggi
Nel caso di altri linguaggi, l'entrypoint assumerà forme del tipo:
ENTRYPOINT ["./main", "$@"]ENTRYPOINT ["java", "Main", "$@"]ENTRYPOINT ["julia", "main.jl", "$@"]- etc ...
Procediamo quindi al build e push dell'immagine Docker eseguendo i seguenti comandi.
Il registry Docker può essere di due tipi:
- Utilizzare un registry pubblicamente accessibile
- Utilizzare un registry accessibile dalla piattaforma ALIDA, nel cui caso occorre contattare l'amministratore.
docker build -t <dominio-registry-docker>:<porta>/<percorso-immagine>:<tag> .
docker login <dominio-registry-docker>:<porta> -u <username_docker>
docker push <dominio-registry-docker>:<porta>/<percorso-immagine>:<tag>
4. Registrazione del Service creato
Con l'immagine caricata sul registry, è possibile registrare il corrispondente Service su ALIDA rendendolo così disponibile a catalogo per la creazione di Workflow.
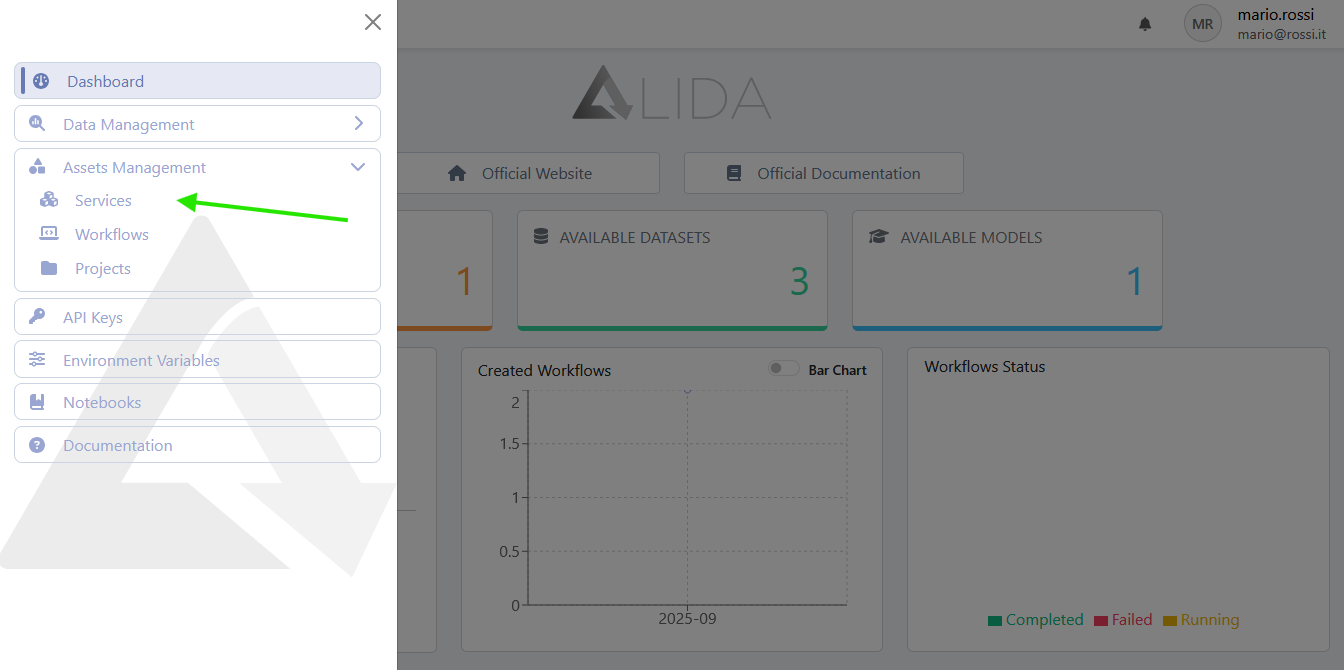
Accediamo al form di registrazione Service come segue:
- Accediamo alla pagina di gestione dei Service dal menù laterale
- Clicchiamo su + Register Service in alto a destra
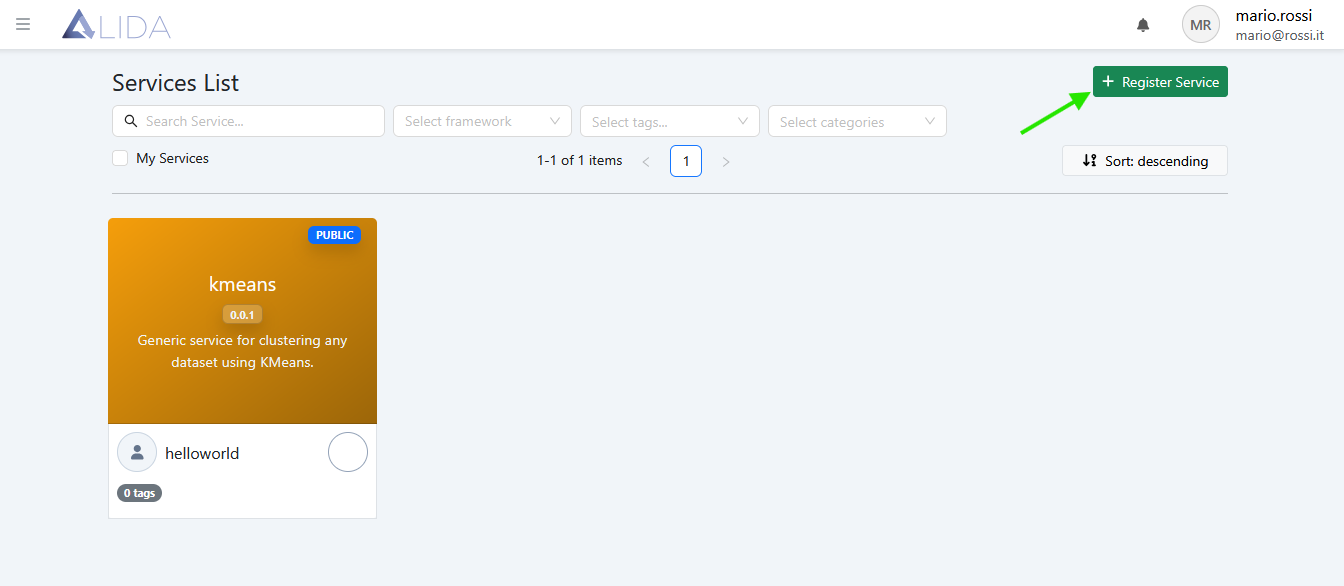
Si aprirà il form di registrazione Service
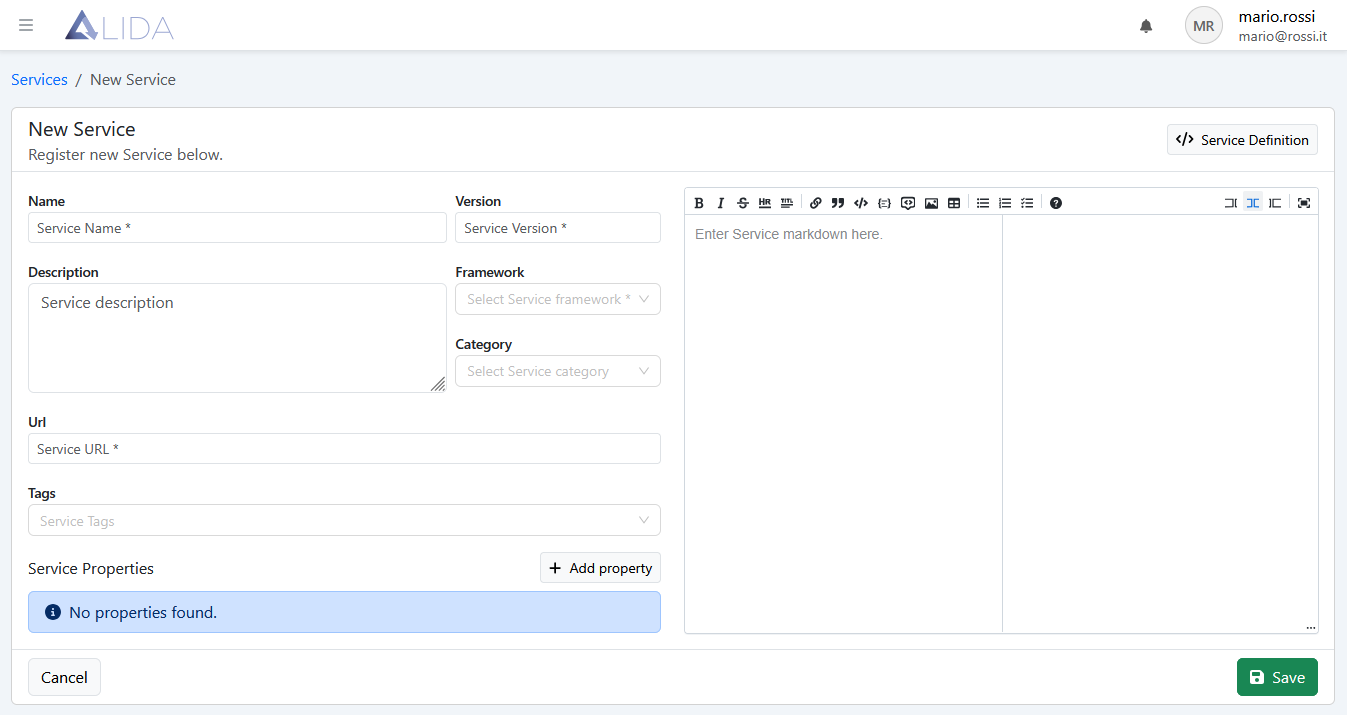
Qui impostiamo per prima cosa i metadati di base per il Service:
- Name:
basic-statistical-indicators - Version:
1.0.0 - URL:
docker://<dominio-tuo-registry-docker>:<porta>/<percorso-immagine>:<tag>
Versionamento dei Service
Il campo Version permette di impostare una versione per il Service che si sta registrando.
Notare come sia possibile definire diverse versioni dello stesso Service aventi la stessa immagine Docker. Questo permette di creare più versioni dello stesso Service diverse l'una dall'altra per esempio per descrizione, documentazione o categorie associate.
Tutte le versioni di un Service compariranno a catalogo e conseguentemente sulla palette del Workflow Designer.
Fatto ciò, passiamo alle Service Properties. Esse comunicano ad ALIDA quali sono le Porte I/O e i Parametri di configurazione del Service che essa dovrà valorizzare prima dell'esecuzione.
Aggiungiamo la prima Service Property al nostro Service per la porta di input: --input-dataset
Cliccare su + Add Property per aprire il form di inserimento:
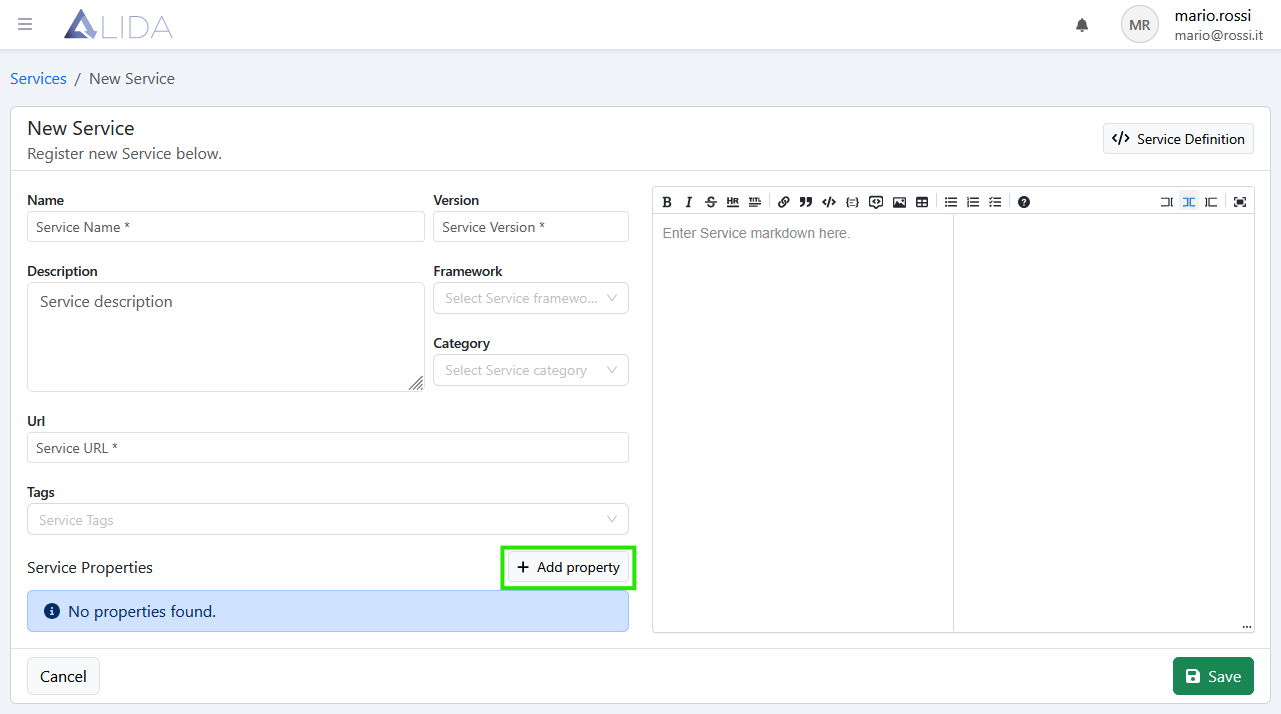
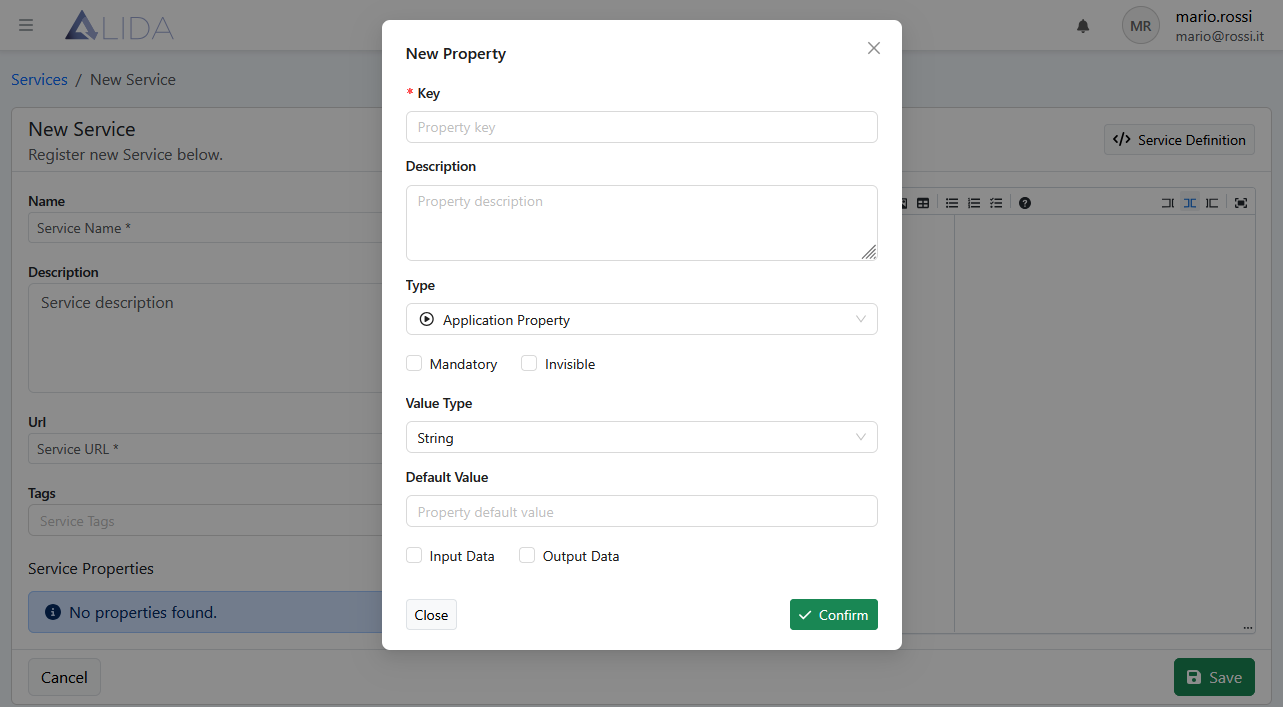
E riempiamo il form come segue --input-dataset:
- Key:
input-dataset - Description: lasciare vuota
- Type:
Application Property - Mandatory:
ticked - Invisible:
ticked - Value Type:
String - Default Value: lasciare vuoto
- Data Type:
Input Data - Streaming:
unticked
e clicchiamo su Confirm
Allo stesso modo creiamo le restanti Service Property:
-
Per
--input-columns:- Key:
input-columns - Description: lasciare vuota
- Type:
Application Property - Mandatory:
ticked - Invisible:
ticked - Value Type:
String - Default Value:
ANY - Data Type:
Input Data - Streaming:
unticked
- Key:
-
Per
--output-dataset:- Key:
output-dataset - Description: lasciare vuota
- Type:
Application Property - Mandatory:
ticked - Invisible:
ticked - Value Type:
String - Default Value: lasciare vuoto
- Data Type:
Output Data - Streaming:
unticked
- Key:
-
Per
--indicators-to-compute:- Key:
indicators-to-compute - Description: lasciare vuota
- Type:
Application Property - Mandatory:
ticked - Invisible:
unticked - Value Type:
String - Default Value: lasciare vuoto
- Data Type:
Input Data - Streaming:
unticked
- Key:
Alla fine avremo le seguenti Service Property:
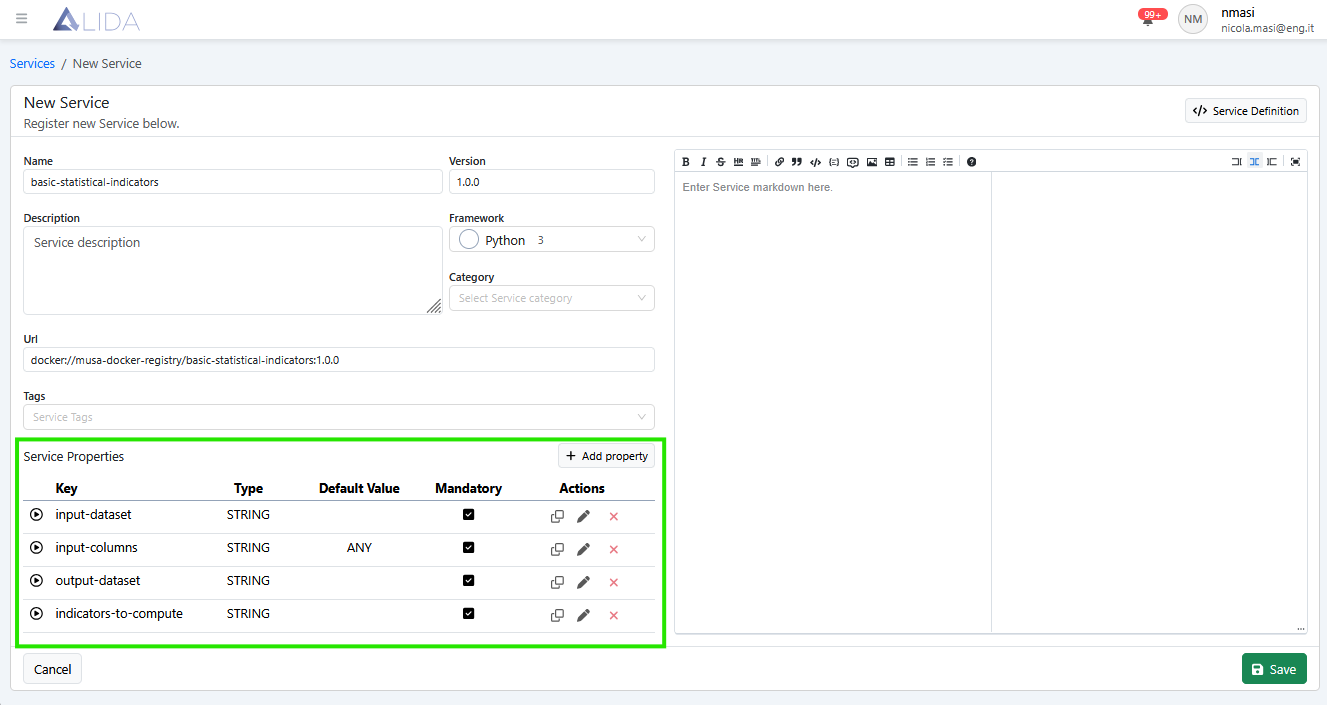
Registriamo il Service completo di properties cliccando su Save in basso a destra:
Una volta salvato comparirà la pagina di dettaglio del Service
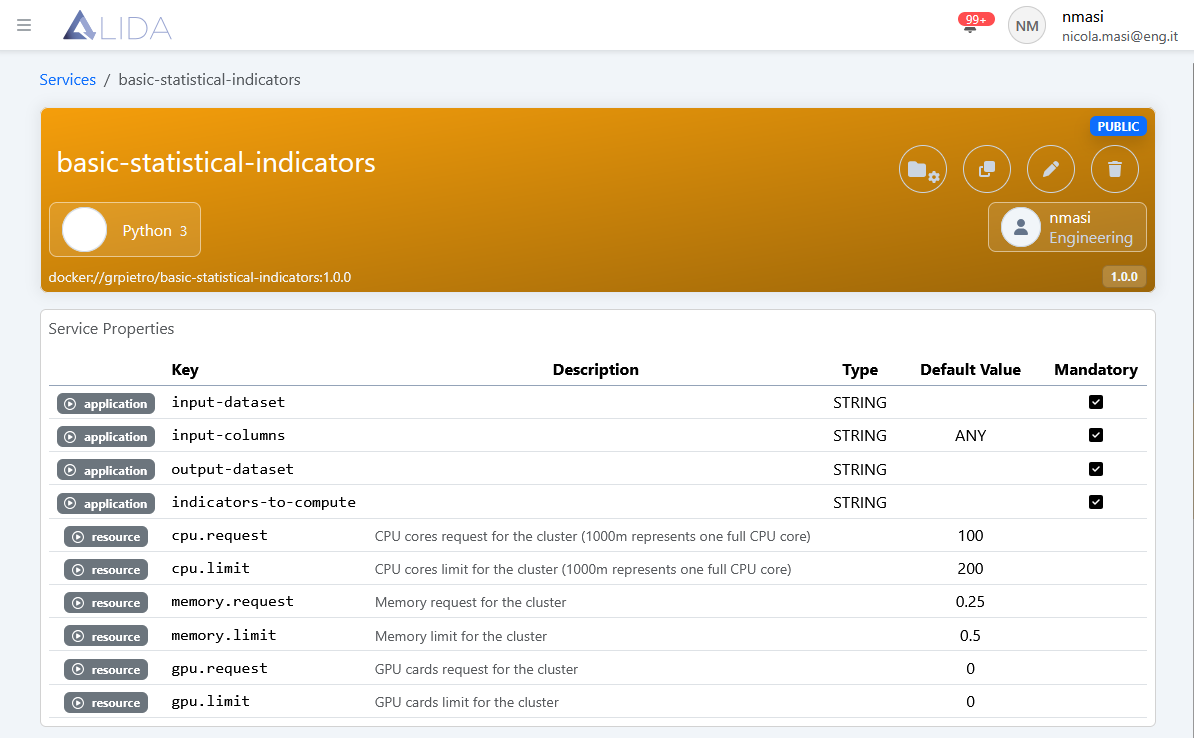
Il Service è adesso disponibile a catalogo e può essere utilizzato per creare un Workflow
Prossimi passi
- Utilizza il Service appena creato in un Workflow (come visto in Primi Passi)
- Visita le sezioni: