Collection of Service Examples
Below you will find a series of service examples. For simplicity, we will provide the metamodel in JSON format. For more information on manual definition, visit:
Ex. 1: Input / Output Dataset type on MinIO
Core program
import argparse
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0', ''):
return False
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_dataset', type=str, required=True)
parser.add_argument('--input-dataset.minio_bucket', dest='input_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset.minIO_URL', dest='input_minio_url', type=str, required=True)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY', dest='input_access_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_SECRET_KEY', dest='input_secret_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_REGION', dest='input_dataset_region_name', type=str, required=True)
parser.add_argument('--input-dataset.use_ssl', dest='input_use_ssl', type=str2bool, required=True)
parser.add_argument('--input-columns', dest='input_columns', type=str, required=False)
parser.add_argument('--output-dataset', dest='output_dataset', type=str, required=True)
parser.add_argument('--output-dataset.minio_bucket', dest='output_minio_bucket', type=str, required=True)
parser.add_argument('--output-dataset.minIO_URL', dest='output_minio_url', type=str, required=True)
parser.add_argument('--output-dataset.minIO_ACCESS_KEY', dest='output_access_key', type=str, required=True)
parser.add_argument('--output-dataset.minIO_SECRET_KEY', dest='output_secret_key', type=str, required=True)
parser.add_argument('--output-dataset.minIO_REGION', dest='output_dataset_region_name', type=str, required=True)
parser.add_argument('--output-dataset.use_ssl', dest='output_use_ssl', type=str2bool, required=True)
args, unknown = parser.parse_known_args()
def minio_ls(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
# Normalize path
if folder.startswith("/"):
folder = folder[1:]
if folder[-1] != "/":
folder = folder + "/"
cleaned = address.replace("http://", "").replace("https://", "")
client = Minio(
cleaned,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
files_list = [x._object_name for x in objects if extention in x._object_name[-len(extention):]]
if len(files_list) > 1:
return ["s3://" + bucket_name + "/" + x for x in files_list]
elif len(files_list) == 1:
return "s3://" + bucket_name + "/" + files_list[0]
else:
raise Exception("Dataset is empty!")
def select_columns(df, colonne: str =None):
if colonne is None or colonne.strip()=='*':
return df
else:
selected_columns = colonne.split(',')
for colonne_b in selected_columns:
colonne_a = colonne_b.strip()
selected_columns[selected_columns.index(colonne_b)] = colonne_a
return df[selected_columns]
def load_from_minio(args):
storage_options = {
'key': args.input_access_key,
'secret': args.input_secret_key,
'region': args.input_region,
'client_kwargs': {
'endpoint_url': args.input_minio_url
}
}
file_path = minio_ls(args.input_minio_url, args.input_access_key, args.input_secret_key,args.input_region, args.input_minio_bucket,
args.input_dataset, ".csv", args.input_use_ssl)
dataset = pd.read_csv(file_path, storage_options=storage_options, sep=None, engine='python')
data_out = select_columns(dataset, colonne=args.input_columns)
return data_out
df = load_from_minio(args)
def save_dataset_to_minio(df,args):
storage_options = {
'key': args.output_access_key,
'secret': args.output_secret_key,
'region': args.output_region,
'client_kwargs': {
'endpoint_url': args.output_minio_url
}
}
file_path = f"s3://{args.output_minio_bucket}/{args.output_dataset}/output-dataset.csv"
print(f"[TO_CSV] path={file_path} endpoint={args.output_minio_url} bucket={args.output_minio_bucket}")
df.to_csv(file_path,
storage_options=storage_options,
index=False
)
save_dataset_to_minio(df,args)
Metamodel
{
"name": "example",
"description": "example of input and output data",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/example:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"description": "Your input dataset",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output dataset",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-dataset",
"valueType": "STRING",
"invisible": true
}
]
}
Ex. 2: Input e Output Stream type on kafka
Core program
import argparse
from kafka import KafkaConsumer, KafkaProducer
from arguments import args
# CLI Arguments definition
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_topic', type=str, required=True)
parser.add_argument('--input-dataset.kafka_brokers', dest='input_kafka_brokers', type=str, required=True)
parser.add_argument('--output-dataset', dest='output_topic', type=str, required=True)
parser.add_argument('--output-dataset.kafka_brokers', dest='output_kafka_brokers', type=str, required=True)
args, unknown = parser.parse_known_args()
# Business logic
consumer = KafkaConsumer(
args.input_topic,
bootstrap_servers=args.input_kafka_brokers.split(",")
)
producer = KafkaProducer(
bootstrap_servers=args.output_kafka_brokers.split(",")
)
def _transform_data(input_data):
# Here the service logic has to be implemented
return input_data
for message in consumer:
# Once we get a message, publish it transformed.
data_to_send = _transform_data(message.value)
producer.send(args.output_topic, data_to_send)
Metamodel
{
"name": "consume-and-publish",
"description": "Consume and publish example",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/consume-and-publish:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"defaultValue": null,
"description": "The input channel where to read the text.",
"extra": {
"datasetType": null,
"mode": "streaming"
},
"invisible": true,
"key": "input-dataset",
"mandatory": true,
"type": "application",
"valueType": "STRING"
},
{
"defaultValue": null,
"description": "The output channel to publish to.",
"extra": {
"datasetType": null,
"mode": "streaming"
},
"invisible": true,
"key": "output-dataset",
"mandatory": true,
"type": "application",
"valueType": "STRING"
}
]
}
Ex. 3: Input Dataset and Output Model on MinIO
Core Program Code
import argparse
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
import joblib
import os
from minio import Minio
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0', ''):
return False
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_dataset', type=str, required=True)
parser.add_argument('--input-dataset.minio_bucket', dest='input_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset.minIO_URL', dest='input_minio_url', type=str, required=True)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY', dest='input_access_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_SECRET_KEY', dest='input_secret_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_REGION', dest='input_dataset_region_name', type=str, required=True)
parser.add_argument('--input-dataset.use_ssl', dest='input_use_ssl', type=str2bool, required=True)
parser.add_argument('--input-columns', dest='input_columns', type=str, required=False)
parser.add_argument('--output-model', dest='output_model', type=str, required=True)
parser.add_argument('--output-model.minio_bucket', dest='output_minio_bucket', type=str, required=True)
parser.add_argument('--output-model.minIO_URL', dest='output_minio_url', type=str, required=True)
parser.add_argument('--output-model.minIO_ACCESS_KEY', dest='output_access_key', type=str, required=True)
parser.add_argument('--output-model.minIO_SECRET_KEY', dest='output_secret_key', type=str, required=True)
parser.add_argument('--output-model.minIO_REGION', dest='output_model_region_name', type=str, required=True)
parser.add_argument('--output-model.use_ssl', dest='output_use_ssl', type=str2bool, required=True)
parser.add_argument("--test_split", help="Test fraction from 0 to 1.", type=float, default=0.2)
args, unknown = parser.parse_known_args()
def minio_ls(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
if folder.startswith("/"):
folder = folder[1:]
if folder[-1] != "/":
folder = folder + "/"
cleaned=address.replace("http://", "").replace("https://", "")
client = Minio(
cleaned,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
files_list = [x._object_name for x in objects if extention in x._object_name[-len(extention):]]
if len(files_list) > 1:
return ["s3://" + bucket_name + "/" + x for x in files_list]
elif len(files_list) == 1:
return "s3://" + bucket_name + "/" + files_list[0]
else:
raise Exception("Dataset is empty!")
def upload_file_to_minio(minio_url, access_key, secret_key,region, bucket_name, object_name, local_file_path, use_ssl=False):
# Initialize the MinIO client
address = minio_url.replace("http://", "").replace("https://", "")
client = Minio(address, access_key=access_key, secret_key=secret_key, secure=use_ssl)
# Upload the file
client.fput_object(bucket_name, object_name, local_file_path)
# Load the input dataset
storage_options = {
'key': args.input_access_key,
'secret': args.input_secret_key,
'region': args.input_region,
'client_kwargs': {
'endpoint_url': f'{args.input_minio_url}'
}
}
file_path = minio_ls(args.input_minio_url, args.input_access_key, args.input_secret_key,args.input_region, args.input_minio_bucket, args.input_dataset, ".csv")
dataset = pd.read_csv(file_path, storage_options=storage_options, sep = None, engine = 'python')
if args.input_columns is not None and args.input_columns.strip()!='*':
selected_columns = [c.strip() for c in args.input_columns.split(",")]
df=dataset[selected_columns]
else:
df = dataset.copy()
# Split the dataset into training and testing sets
# Only the training set is used here
df = train_test_split(df, test_size=args.test_split, random_state=42)[0]
# Extract the feature matrix from the dataframe
X = df.values
# Initialize and train a KMeans clustering model
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# Save the trained model locally as a .pkl file
model_folder = "mymodel"
os.makedirs(model_folder, exist_ok=True)
model_local_path = os.path.join(model_folder,"kmeans_model.pkl")
joblib.dump(kmeans, model_local_path)
# Upload to minIo
upload_file_to_minio(args.output_minio_url, args.output_access_key, args.output_secret_key,args.output_region, args.output_minio_bucket, args.output_model, model_local_path, args.output_use_ssl)
Metamodel
{
"name": "kmeans-clustering",
"description": "Kmeans clustering model",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/kmeans-clustering:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"description": "Your input dataset description.",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset",
"valueType": "STRING"
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns",
"type": "application",
"mandatory": true,
"valueType": "STRING"
"invisible": true
},
{
"description": "Your model description",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-model",
"valueType": "STRING"
"invisible": true
},
{
"description": "Test fraction from 0 to 1",
"mandatory": true,
"type": "application",
"defaultValue": 0.2,
"key": "test_split",
"valueType": "DOUBLE"
}
]
}
Ex. 4: Input Dataset + Input Model + Output Model
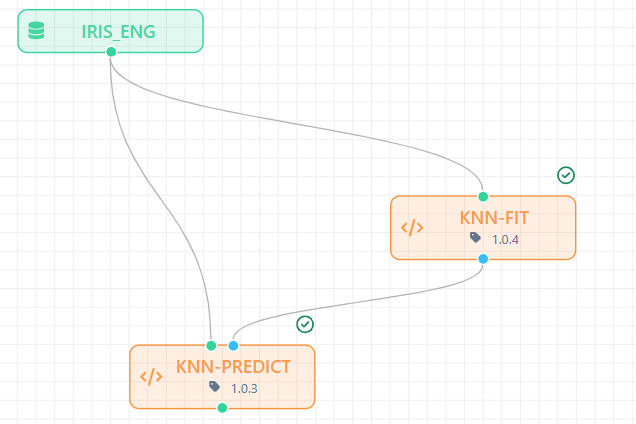
Core Program Code
import argparse
import pandas as pd
from arguments import args
from joblib import load
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_dataset', type=str, required=True)
parser.add_argument('--input-dataset.minio_bucket', dest='input_dataset_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset.minIO_URL', dest='input_dataset_minio_url', type=str, required=True)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY', dest='input_dataset_access_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_SECRET_KEY', dest='input_dataset_secret_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_REGION', dest='input_dataset_region_name', type=str, required=True)
parser.add_argument('--input-model', dest='input_model', type=str, required=True)
parser.add_argument('--input-model.minio_bucket', dest='input_model_minio_bucket', type=str, required=True)
parser.add_argument('--input-model.minIO_URL', dest='input_model_minio_url', type=str, required=True)
parser.add_argument('--input-model.minIO_ACCESS_KEY', dest='input_model_access_key', type=str, required=True)
parser.add_argument('--input-model.minIO_SECRET_KEY', dest='input_model_secret_key', type=str, required=True)
parser.add_argument('--input-model.minIO_REGION', dest='input_model_region_name', type=str, required=True)
parser.add_argument('--output-dataset', dest='output_dataset', type=str, required=True)
parser.add_argument('--output-dataset.minio_bucket', dest='output_minio_bucket', type=str, required=True)
parser.add_argument('--output-dataset.minIO_URL', dest='output_minio_url', type=str, required=True)
parser.add_argument('--output-dataset.minIO_ACCESS_KEY', dest='output_access_key', type=str, required=True)
parser.add_argument('--output-dataset.minIO_SECRET_KEY', dest='output_secret_key', type=str, required=True)
parser.add_argument('--output-dataset.minIO_REGION', dest='output_dataset_region_name', type=str, required=True)
parser.add_argument("--predColName", dest='predColName'. help="Name of the column containing the predictions", type=str, default="prediction")
args, unknown = parser.parse_known_args()
def minio_ls(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
if folder[-1] != "/":
folder = folder + "/"
client = Minio(
address,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
files_list = [x._object_name for x in objects if extention in x._object_name[-len(extention):]]
if len(files_list) > 1:
return ["s3://" + bucket_name + "/" + x for x in files_list]
elif len(files_list) == 1:
return "s3://" + bucket_name + "/" + files_list[0]
else:
raise Exception("Dataset is empty!")
def load_first_from_minio(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
if folder[-1] != "/":
folder = folder + "/"
client = Minio(
address,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
# Find the first model file
model_file = next((obj for obj in objects if obj._object_name.endswith(extention)), None)
# Get the filename from the object name
filename = os.path.basename(model_file.object_name)
local_file_path = filename
# Download the file
client.fget_object(bucket_name, model_file.object_name, local_file_path)
return local_file_path
def upload_file_to_minio(minio_url, access_key, secret_key,region, bucket_name, object_name, local_file_path):
# Initialize the MinIO client
client = Minio(minio_url, access_key=access_key, secret_key=secret_key,region=region, secure=False)
# Upload the file
client.fput_object(bucket_name, object_name, local_file_path)
def predict():
model_path = load_first_from_minio(args.input_model_minio_url, args.input_model_access_key, args.input_model_secret_key,args.input_model_region_name, args.input_model_minio_bucket, args.input_model, ".joblib")
knn = load(model_path)
storage_options = {
'key': args.input_dataset_access_key,
'secret': args.input_dataset_secret_key,
'region': args.input_dataset_region_name,
'client_kwargs': {
'endpoint_url': f'{args.input_minio_url}'
}
}
file_path = minio_ls(args.input_dataset_minio_url, args.input_dataset_access_key, args.input_dataset_secret_key,args.input_dataset_region_name, args.input_dataset_minio_bucket, args.input_dataset, ".csv")
dataset = pd.read_csv(file_path, storage_options=storage_options, sep = None, engine = 'python')
colonne = args.input_columns
if colonne is not None and colonne.strip()!='*':
df_selected = dataset[c.strip() for c in colonne.split(",")]
dataset = df_selected.copy()
result = knn.predict(dataset)
result = pd.DataFrame(result, columns = [args.predColName])
dataset[args.predColName] = result[args.predColName]
return dataset
df = predict()
storage_options = {
'key': args.output_access_key,
'secret': args.output_secret_key,
'region': args.output_region,
'client_kwargs': {
'endpoint_url': f'{args.output_minio_url}'
}
}
file_path = f"s3://{args.output_minio_bucket}/{args.output_dataset}/dataset.csv"
df.to_csv(file_path,
storage_options=storage_options,
index=False
)
Metamodel
{
"name": "knn-predict",
"description": "Knn prediction model",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/knn-predict:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"description": "Your input dataset description.",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your input model description",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-model",
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output dataset",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-dataset",
"valueType": "STRING",
"invisible": true
},
{
"description": "Name of the column containing the predictions",
"mandatory": true,
"type": "application",
"defaultValue": "prediction",
"key": "predColName",
"valueType": "STRING"
}
]
}
Ex. 5: Prediction Input Stream + Input Model + Output Stream
Core Program Code
import argparse
import os
from pathlib import Path
import dill
import joblib
import pickle
import numpy as np
import pandas as pd
from alibi.explainers import AnchorTabular
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_topic', type=str, required=True)
parser.add_argument('--input-dataset.kafka_brokers', dest='input_kafka_brokers', type=str, required=True)
parser.add_argument('--output-dataset', dest='output_topic', type=str, required=True)
parser.add_argument('--output-dataset.kafka_brokers', dest='output_kafka_brokers', type=str, required=True)
parser.add_argument('--input-model', dest='input_model', type=str, required=True)
parser.add_argument('--input-model.minio_bucket', dest='input_model_minio_bucket', type=str, required=True)
parser.add_argument('--input-model.minIO_URL', dest='input_model_minio_url', type=str, required=True)
parser.add_argument('--input-model.minIO_ACCESS_KEY', dest='input_model_access_key', type=str, required=True)
parser.add_argument('--input-model.minIO_SECRET_KEY', dest='input_model_secret_key', type=str, required=True)
parser.add_argument('--input-model.minIO_REGION', dest='input_model_region_name', type=str, required=True)
parser.add_argument("--feature_to_predict", dest='feature_to_predict', help="These arguments will be injected directly into the explain method of the Anchor Tabular explainer.", required=False, type=str)
parser.add_argument("--direct_args_to_explainer_function", dest='direct_args_to_explainer_function', help="This args are going to be injected to the KNeighborsClassifier.fit function directly", type=str, default='{"n_neighbors":3}')
args, unknown = parser.parse_known_args()
def load_first_from_minio(address, access_key, secret_key,region, bucket_name, folder, use_ssl=False):
if folder[-1] != "/":
folder = folder + "/"
client = Minio(
address,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
# Find the first model file
model_file = next((obj for obj in objects if (obj.object_name.endswith(".joblib") or obj.object_name.endswith(".sav") or obj.object_name.endswith(".pkl"))), None)
# Get the filename from the object name
filename = os.path.basename(model_file.object_name)
local_file_path = filename
# Download the file
client.fget_object(bucket_name, model_file.object_name, local_file_path)
return local_file_path
def find_folder(parent_path, folder_name):
"""
Recursively searches for a folder with the specified name inside the given parent directory.
Only directories (not files) are considered.
:param parent_path: Path to the root directory where the search should begin.
:param folder_name: Name of the folder to find.
:return: Full path to the found folder.
:raises FileNotFoundError: If the folder is not found under the given path.
"""
if not os.path.exists(parent_path):
raise FileNotFoundError(f"The directory '{parent_path}' does not exist.")
if not os.path.isdir(parent_path):
raise NotADirectoryError(f"The path '{parent_path}' is not a directory.")
for root, dirs, _ in os.walk(parent_path):
if folder_name in dirs:
return os.path.join(root, folder_name)
def download_folder_from_minio(endpoint, access_key, secret_key,region, bucket, path, destination, secure=False):
cleaned = endpoint.replace("http://", "").replace("https://", "")
client = Minio(
cleaned,
access_key=access_key,
secret_key=secret_key,
secure=secure,
region=region
)
# Normalizza
if path.startswith("/"):
path = path[1:]
if path and not path.endswith("/"):
path += "/"
objects = client.list_objects(bucket, prefix=path, recursive=True)
found = False
for obj in objects:
found = True
rel_path = obj.object_name[len(path):].lstrip("/")
local_path = os.path.join(destination, rel_path)
os.makedirs(os.path.dirname(local_path), exist_ok=True)
client.fget_object(bucket, obj.object_name, local_path)
print(f"Downloaded {obj.object_name} -> {local_path}", flush=True)
if not found:
print(f"Nessun file trovato in {bucket}/{path}", flush=True)
def build_predict_fn(model):
if not hasattr(model, 'predict'):
raise AttributeError("The provided model does not have a 'predict' method.")
if hasattr(model, 'feature_names_in_'):
return lambda x: model.predict(pd.DataFrame(x, columns=model.feature_names_in_.tolist()))
else:
print('engine trained without features', flush=True)
return lambda x: model.predict(x)
def load_anchor_explainer(explainer_folder_path: str) -> AnchorTabular:
"""
Loads an AnchorTabular explainer saved with dill from a specific folder,
including restoring the sampler.
:param explainer_folder_path: path to the /output_model/explainer_model folder
:return: an AnchorTabular instance already fitted and ready to use
"""
explainer_file = Path(explainer_folder_path) / 'explainer.dill'
sampler_file = Path(explainer_folder_path) / 'samplers.dill'
discretizer_file = Path(explainer_folder_path) / 'discretizer.dill'
if not explainer_file.exists():
raise FileNotFoundError(f"Explainer file not found at {explainer_file}")
with open(explainer_file, 'rb') as f:
explainer: AnchorTabular = dill.load(f)
# Restore samplers separately
if discretizer_file.exists():
if sampler_file.exists():
with open(discretizer_file, 'rb') as f:
discretizer = dill.load(f)
with open(sampler_file, 'rb') as f:
samplers = dill.load(f)
samplers.disc = discretizer
explainer.samplers = [samplers]
print("✅ Samplers successfully reloaded from the explainer.", flush=True)
else:
print("⚠ Warning: samplers.dill not found. The explainer may not work correctly.", flush=True)
return explainer
def extract_imputer_values_from_explainer(explainer) -> dict:
"""
Extracts a single dictionary {feature_name: fill_value} consistent with training.
- Central value of qts for numerical features (from the Discretizer)
- First available value for categorical features (from feature_values)
Returns:
Dict[str, Any]: mapping {column_name: fill_value}
"""
sampler = explainer.samplers[0]
discretizer = sampler.disc
feature_names = explainer.feature_names
fill_values = {}
# Central value (median approximation) for numerical features
for i in explainer.numerical_features:
if i in discretizer.lambdas and 'qts' in discretizer.lambdas[i].keywords:
qts = discretizer.lambdas[i].keywords['qts']
if len(qts) > 0:
fill_values[feature_names[i]] = qts[len(qts) // 2]
# First known value for categorical features
for i in sampler.categorical_features:
if i in sampler.feature_values and len(sampler.feature_values[i]) > 0:
fill_values[feature_names[i]] = sampler.feature_values[i][0]
return fill_values
def get_anchors_results_with_prediction(sample_to_explain, fitted_anchors: AnchorTabular, explain_kwargs, target_class: str):
try:
encoded_instance = encode_categorical_features(sample_to_explain, fitted_anchors)
explanation = fitted_anchors.explain(encoded_instance,**explain_kwargs)
anch_explanation = explanation['data']
except Exception as e:
print('While getting anchors results, an error occured:', flush=True)
print(e, flush=True)
anch_explanation = None
try:
prediction = fitted_anchors.predictor(sample_to_explain.reshape(1,-1))[0]
except Exception as e:
print('While getting prediction, an error occured:', flush=True)
print(e, flush=True)
prediction = None
anchor_text = ' AND '.join(anch_explanation.get('anchor', [])) if anch_explanation else ''
return {
'name': target_class,
'value': str(prediction),
'explanation': anchor_text
}
import pandas as pd
from arguments import args
import pickle
import joblib
from utils import load_first_from_minio, minio_ls
from utils import *
from kafka import KafkaConsumer, KafkaProducer
model_path_str = load_first_from_minio(args.input_model_minio_url, args.input_model_access_key, args.input_model_secret_key,args.input_model_region_name, args.input_model_minio_bucket, args.input_model, ".joblib")
model_to_explain = None
try:
model_to_explain = joblib.load(model_path_str)
except Exception:
try:
with open(model_to_explain, "rb") as f:
model_to_explain = pickle.load(f)
except Exception as e:
raise RuntimeError(f"Failed to load model {model_path_str}: {e}")
try:
features_name_for_model = model_to_explain.feature_names_in_.tolist()
except AttributeError:
features_name_for_model = None
predict_fn = build_predict_fn(model_to_explain)
explainer_remote_path = '.resources/input_model'
os.makedirs(explainer_remote_path, exist_ok=True)
download_folder_from_minio(args.input_model_minio_url, args.input_model_access_key, args.input_model_secret_key,args.input_model_region_name, args.input_model_minio_bucket, args.input_model, explainer_remote_path, secure=False)
explainer_path = find_folder(explainer_remote_path, 'explainer_model')
explainer = load_anchor_explainer(explainer_path)
# Check if this step is still needed
explainer.reset_predictor(predict_fn)
# Load information to impute missing values consistently with the explainer
impute_dict = extract_imputer_values_from_explainer(explainer)
direct_args_to_explainer_function = json.loads(args.direct_args_to_explainer_function)
if direct_args_to_explainer_function is None: direct_args_to_explainer_function = {}
if 'threshold' not in direct_args_to_explainer_function: direct_args_to_explainer_function['threshold'] = 0.7
if args.feature_to_predict is None: args.feature_to_predict = 'predicted_label'
consumer = KafkaConsumer(
args.input_topic,
bootstrap_servers=args.input_kafka_brokers.split(",")
)
producer = KafkaProducer(
bootstrap_servers=args.output_kafka_brokers.split(",")
)
for message in consumer.read_message():
if isinstance(message, dict):
records = [message]
elif isinstance(message, list) and all(isinstance(el, dict) for el in message):
records = message
else:
print("⚠ Messaggio non valido (né dict né lista di dict), ignorato.")
continue
df_input = pd.DataFrame(records)
# Imposta il valore nullo per feature non arrivate nel messaggio ma necessarie per il modello
if features_name_for_model is not None:
missing_features = [col for col in features_name_for_model if col not in df_input.columns]
for col in missing_features:
df_input[col] = np.nan
df_input = df_input[features_name_for_model]
# imputazione valori mancanti
df_input.fillna(impute_dict, inplace=True)
# Iterazione riga per riga per prediction + explanation
for (i), row in df_input.iterrows():
input_array = row.to_numpy(dtype=object)
try:
anchor_explain_dict = get_anchors_results_with_prediction(
sample_to_explain=input_array,
fitted_anchors=explainer,
explain_kwargs=args.direct_args_to_explainer_function,
target_class=args.feature_to_predict
)
# Inserimento in record originale SENZA toccare altre chiavi
record = records[i]
record.setdefault('predictions', []).append(anchor_explain_dict)
except Exception as e:
print('Error of elaboration messages:', flush=True)
print(e, flush=True)
producer.send(args.output_topic, records)
Metamodel
{
"accessLevel": "PUBLIC",
"description": "Anchors explainer for tabular data",
"mode": "BATCH",
"name": "anchors-tabular-predict",
"properties": [
{
"defaultValue": null,
"description": "The feature to predict. Use for multiple pretiction",
"invisible": false,
"key": "feature_to_predict",
"mandatory": false,
"type": "application",
"valueType": "STRING"
},
{
"defaultValue": null,
"description": "These arguments will be injected directly into the explain method of the Anchor Tabular explainer.",
"invisible": false,
"key": "direct_args_to_explainer_function",
"mandatory": false,
"type": "application",
"valueType": "JSON"
},
{
"defaultValue": null,
"description": "Your input model description.",
"inputData": false,
"invisible": true,
"key": "input-model",
"mandatory": true,
"type": "application",
"valueType": "STRING"
},
{
"defaultValue": null,
"description": "Data with prediction and explanations",
"extra": {
"datasetType": null,
"mode": "streaming"
},
"invisible": true,
"key": "output-dataset",
"mandatory": true,
"type": "application",
"valueType": "STRING"
},
{
"defaultValue": null,
"description": "Data to be explained.",
"extra": {
"datasetType": null,
"mode": "streaming"
},
"invisible": true,
"key": "input-dataset",
"mandatory": true,
"type": "application",
"valueType": "STRING"
}
],
"url": "docker://dockerhub.alidalab.it/alida/restricted/services/anchors-tabular-predict:1.1.0",
"version": "1.1.0"
}
Ex. 6: Multiple Input Datasets + Multiple Output Datasets
Core Program Code
import argparse
from minio import Minio
from arguments import args
from utils import upload_dataset, fetch_dataset
import pandas as pd
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset-1', dest='input_dataset_1', type=str, required=True)
parser.add_argument('--input-dataset-1.minio_bucket', dest='input_dataset_1_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset-1.minIO_URL', dest='input_dataset_1_minio_url', type=str, required=True)
parser.add_argument('--input-dataset-1.minIO_ACCESS_KEY', dest='input_dataset_1_access_key', type=str, required=True)
parser.add_argument('--input-dataset-1.minIO_SECRET_KEY', dest='input_dataset_1_secret_key', type=str, required=True)
parser.add_argument('--input-dataset-1.minIO_REGION', dest='input_dataset_1_region_name', type=str, required=True)
parser.add_argument('--output-dataset-1', dest='output_dataset_1_dataset', type=str, required=True)
parser.add_argument('--output-dataset-1.minio_bucket', dest='output_dataset_1_minio_bucket', type=str, required=True)
parser.add_argument('--output-dataset-1.minIO_URL', dest='output_dataset_1_minio_url', type=str, required=True)
parser.add_argument('--output-dataset-1.minIO_ACCESS_KEY', dest='output_dataset_1_access_key', type=str, required=True)
parser.add_argument('--output-dataset-1.minIO_SECRET_KEY', dest='output_dataset_1_secret_key', type=str, required=True)
parser.add_argument('--output-dataset-1.minIO_REGION', dest='output_dataset_1_region_name', type=str, required=True)
parser.add_argument('--input-dataset-2', dest='input_dataset_2', type=str, required=True)
parser.add_argument('--input-dataset-2.minio_bucket', dest='input_dataset_2_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset-2.minIO_URL', dest='input_dataset_2_minio_url', type=str, required=True)
parser.add_argument('--input-dataset-2.minIO_ACCESS_KEY', dest='input_dataset_2_access_key', type=str, required=True)
parser.add_argument('--input-dataset-2.minIO_SECRET_KEY', dest='input_dataset_2_secret_key', type=str, required=True)
parser.add_argument('--input-dataset-2.minIO_REGION', dest='input_dataset_2_region_name', type=str, required=True)
parser.add_argument('--output-dataset-2', dest='output_dataset_2_dataset', type=str, required=True)
parser.add_argument('--output-dataset-2.minio_bucket', dest='output_dataset_2_minio_bucket', type=str, required=True)
parser.add_argument('--output-dataset-2.minIO_URL', dest='output_dataset_2_minio_url', type=str, required=True)
parser.add_argument('--output-dataset-2.minIO_ACCESS_KEY', dest='output_dataset_2_access_key', type=str, required=True)
parser.add_argument('--output-dataset-2.minIO_SECRET_KEY', dest='output_dataset_2_secret_key', type=str, required=True)
parser.add_argument('--output-dataset-2.minIO_REGION', dest='output_dataset_2_region_name', type=str, required=True)
parser.add_argument('--input-dataset-3', dest='input_dataset_3', type=str, required=True)
parser.add_argument('--input-dataset-3.minio_bucket', dest='input_dataset_3_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset-3.minIO_URL', dest='input_dataset_3_minio_url', type=str, required=True)
parser.add_argument('--input-dataset-3.minIO_ACCESS_KEY', dest='input_dataset_3_access_key', type=str, required=True)
parser.add_argument('--input-dataset-3.minIO_SECRET_KEY', dest='input_dataset_3_secret_key', type=str, required=True)
parser.add_argument('--input-dataset-3.minIO_REGION', dest='input_dataset_3_region_name', type=str, required=True)
parser.add_argument('--output-dataset-3', dest='output_dataset_3_dataset', type=str, required=True)
parser.add_argument('--output-dataset-3.minio_bucket', dest='output_dataset_3_minio_bucket', type=str, required=True)
parser.add_argument('--output-dataset-3.minIO_URL', dest='output_dataset_3_minio_url', type=str, required=True)
parser.add_argument('--output-dataset-3.minIO_ACCESS_KEY', dest='output_dataset_3_access_key', type=str, required=True)
parser.add_argument('--output-dataset-3.minIO_SECRET_KEY', dest='output_dataset_3_secret_key', type=str, required=True)
parser.add_argument('--output-dataset-3.minIO_REGION', dest='output_dataset_3_region_name', type=str, required=True)
args, unknown = parser.parse_known_args()
def minio_ls(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
if folder[-1] != "/":
folder = folder + "/"
client = Minio(
address,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
files_list = [x._object_name for x in objects if extention in x._object_name[-len(extention):]]
if len(files_list) > 1:
return ["s3://" + bucket_name + "/" + x for x in files_list]
elif len(files_list) == 1:
return "s3://" + bucket_name + "/" + files_list[0]
else:
raise Exception("Dataset is empty!")
def fetch_dataset(dataset, minio_url, access_key, secret_key,region, bucket_name, extention):
storage_options = {
'key': access_key,
'secret': secret_key,
'region': region,
'client_kwargs': {
'endpoint_url': f'{minio_url}'
}
}
file_path = minio_ls(minio_url, access_key, secret_key,region, bucket_name, dataset, extention)
input_dataset = pd.read_csv(file_path, storage_options=storage_options, sep = None, engine = 'python')
return input_dataset
def upload_dataset(df, path, minio_url, access_key, secret_key, bucket_name):
storage_options = {
'key': access_key,
'secret': secret_key,
'region': region,
'client_kwargs': {
'endpoint_url': f'{minio_url}'
}
}
file_path = f"s3://{bucket_name}/{path}/dataset.csv"
df.to_csv(file_path,
storage_options=storage_options,
index=False
)
input_dataset_1 = fetch_dataset(args.input_dataset_1_minio_url, args.input_dataset_1_access_key, args.input_dataset_1_secret_key,args.input_dataset_1_region_name, args.input_dataset_1_minio_bucket, args.input_dataset_1_dataset, ".csv")
input_dataset_2 = fetch_dataset(args.input_dataset_2_minio_url, args.input_dataset_2_access_key, args.input_dataset_2_secret_key,args.input_dataset_2_region_name, args.input_dataset_2_minio_bucket, args.input_dataset_2_dataset, ".csv")
input_dataset_3 = fetch_dataset(args.input_dataset_3_minio_url, args.input_dataset_3_access_key, args.input_dataset_3_secret_key,args.input_dataset_3_region_name, args.input_dataset_3_minio_bucket, args.input_dataset_3_dataset, ".csv")
# Add the "Status" column with "Updated" in every row
input_dataset_1['Status'] = 'Updated 1'
input_dataset_2['Status'] = 'Updated 2'
input_dataset_3['Status'] = 'Updated 3'
upload_dataset(input_dataset_1, args.output_dataset_1_dataset, args.output_dataset_1_minio_url, args.output_dataset_1_access_key, args.output_dataset_1_secret_key,args.output_dataset_1_region_name, args.output_dataset_1_minio_bucket)
upload_dataset(input_dataset_2, args.output_dataset_2_dataset, args.output_dataset_2_minio_url, args.output_dataset_2_access_key, args.output_dataset_2_secret_key,args.output_dataset_2_region_name, args.output_dataset_2_minio_bucket)
upload_dataset(input_dataset_3, args.output_dataset_3_dataset, args.output_dataset_3_minio_url, args.output_dataset_3_access_key, args.output_dataset_3_secret_key,args.output_dataset_3_region_name, args.output_dataset_3_minio_bucket)
Metamodel
{
"name": "multiple-io-example",
"description": "Multiple IO example",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/multiple-io-example:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"description": "Your input dataset 1",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset-1",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns-1",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your input dataset 2",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset-2",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns-2",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your input dataset 3",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset-3",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns-3",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output dataset 1",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-dataset-1",
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output dataset 2",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-dataset-2",
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output dataset 3",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-dataset-3",
"valueType": "STRING",
"invisible": true
}
]
}
Ex. 7: Input Dataset + Output Model + Workflow Media
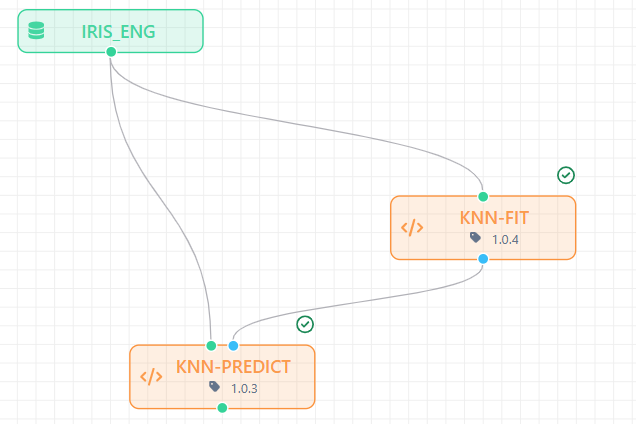
Core Program Code
import argparse
import os
from minio import Minio
from arguments import args
from kafka import KafkaProducer
import pandas as pd
from arguments import args
from sklearn.neighbors import KNeighborsClassifier
from joblib import dump, load
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
from utilities import minio_ls, prepare_file_metadata, upload_file_to_minio
from producer import send_message
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_dataset', type=str, required=True)
parser.add_argument('--input-dataset.minio_bucket', dest='input_dataset_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset.minIO_URL', dest='input_dataset_minio_url', type=str, required=True)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY', dest='input_dataset_access_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_SECRET_KEY', dest='input_dataset_secret_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_REGION', dest='input_dataset_region_name', type=str, required=True)
parser.add_argument('--output-model', dest='output_model', type=str, required=True)
parser.add_argument('--output-model.minio_bucket', dest='output_model_minio_bucket', type=str, required=True)
parser.add_argument('--output-model.minIO_URL', dest='output_model_minio_url', type=str, required=True)
parser.add_argument('--output-model.minIO_ACCESS_KEY', dest='output_model_access_key', type=str, required=True)
parser.add_argument('--output-model.minIO_SECRET_KEY', dest='output_model_secret_key', type=str, required=True)
parser.add_argument('--output-model.minIO_REGION', dest='output_model_region_name', type=str, required=True)
parser.add_argument('--go_manager.brokers', dest='go_manager_brokers', type=str, required=True)
parser.add_argument('--go_manager_topic', dest='go_manager_topic', type=str, required=True)
parser.add_argument('--go_manager', dest='minio_path', type=str, required=True)
parser.add_argument('--go_manager.minio_bucket', dest='minio_bucket', type=str, required=True)
parser.add_argument('--go_manager.minIO_URL', dest='minio_url', type=str, required=True)
parser.add_argument('--go_manager.minIO_ACCESS_KEY', dest='minio_access_key', type=str, required=True)
parser.add_argument('--go_manager.minIO_SECRET_KEY', dest='minio_secret_key', type=str, required=True)
parser.add_argument('--go-manager.minIO_REGION', dest='go_manager_region_name', type=str, required=True)
parser.add_argument("--labelCol", dest='labelCol'. help="Name of the column containing the label", type=str, required=True)
parser.add_argument("--direct_args_to_sklearn_function", dest='direct_args_to_sklearn_function'. help="This args are going to be injected to the KNeighborsClassifier.fit function directly", type=str, default='{"n_neighbors":3}')
args, unknown = parser.parse_known_args()
def minio_ls(address, access_key, secret_key,region, bucket_name, folder, extention, use_ssl=False):
if folder[-1] != "/":
folder = folder + "/"
client = Minio(
address,
access_key=access_key,
secret_key=secret_key,
secure=use_ssl,
region=region
)
objects = client.list_objects(bucket_name=bucket_name, prefix=folder)
files_list = [x._object_name for x in objects if extention in x._object_name[-len(extention):]]
if len(files_list) > 1:
return ["s3://" + bucket_name + "/" + x for x in files_list]
elif len(files_list) == 1:
return "s3://" + bucket_name + "/" + files_list[0]
else:
raise Exception("Dataset is empty!")
def upload_file_to_minio(minio_url, access_key, secret_key,region, bucket_name, object_name, local_file_path):
# Initialize the MinIO client
client = Minio(minio_url, access_key=access_key, secret_key=secret_key,region=region, secure=False)
# Upload the file
client.fput_object(bucket_name, object_name, local_file_path)
def prepare_metadata_json(name, messageType, title=None, description=None, var=None, show=True):
result = {
"name": name,
"key": name.lower().replace(" ", "-"),
"uuid": str(uuid.uuid4()),
"messageType": messageType,
"title": title,
"description": description,
"var": var,
"created": str(datetime.now()),
"modified": str(datetime.now()),
"show": show
}
if "SERVICE_ID" in os.environ:
result['serviceId'] = os.environ.get('SERVICE_ID')
if "EXECUTION_ID" in os.environ:
result['executionId'] = os.environ.get('EXECUTION_ID')
if "HASH_TOKEN" in os.environ:
result['hashToken'] = os.environ.get('HASH_TOKEN')
return result
def prepare_file_metadata(name, path, extension, filename):
metadata = prepare_metadata_json(name=name, messageType="picture")
metadata['path'] = path
metadata['extension'] = extension
metadata['filename'] = filename
return metadata
producer = KafkaProducer(bootstrap_servers=args.go_manager_brokers.split(","))
def send_message(data):
producer.send(args.go_manager_topic, json.dumps(data).encode('utf-8'))
producer.flush()
# Load the input dataset
storage_options = {
'key': args.input_access_key,
'secret': args.input_secret_key,
'region': args.input_region,
'client_kwargs': {
'endpoint_url': f'{args.input_minio_url}'
}
}
file_path = minio_ls(args.input_dataset_minio_url, args.input_dataset_access_key, args.input_dataset_secret_key,args.input_dataset_region_name, args.input_dataset_minio_bucket, args.input_dataset, ".csv")
dataset = pd.read_csv(file_path, storage_options=storage_options)
y = dataset[args.labelCol]
X = dataset.drop(args.labelCol, axis=1)
neigh = KNeighborsClassifier(json.loads(args.direct_args_to_sklearn_function))
neigh.fit(X=X, y=y)
# Saves plot in local path
disp = ConfusionMatrixDisplay.from_estimator(neigh, X, y)
disp.plot()
disp.ax_.set_title("Confusion Matrix")
plt.savefig("conf_matrix.png")
metadata = prepare_file_metadata("Confusion Matrix", "conf_matrix.png", "png", "conf_matrix.png")
#Send plot to minIo
upload_file_to_minio(args.minio_url, args.minio_access_key, args.minio_secret_key,args.minio_region_name, args.minio_bucket, args.minio_path, 'conf_matrix.png')
send_message(metadata)
# Save the trained model locally as a .joblib fil
model_path = "./temp"
os.makedirs(model_path, exist_ok=True)
dump(neigh, os.path.join(model_path, 'model.joblib'))
# Upload to minIo
upload_file_to_minio(args.output_model_minio_url, args.output_model_access_key, args.output_model_secret_key,args.minio_region_name, args.output_model_minio_bucket, args.output_model, model_path)
Metamodel
{
"name": "knn-fit",
"description": "Knn model training",
"mode": "BATCH",
"url": "docker://gitlab.alidalab.it:5000/alida/analytics/python-applications/knn-fit:1.0.0",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"properties": [
{
"description": "Your input dataset description.",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset",
"valueType": "STRING",
"invisible": true
},
{
"defaultValue": "ANY",
"description": "Selected columns from table",
"key": "input-columns",
"type": "application",
"mandatory": true,
"valueType": "STRING",
"invisible": true
},
{
"description": "Your model description",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-model",
"valueType": "STRING",
"invisible": true
},
{
"description": "Name of the column containing the label",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "labelCol",
"valueType": "STRING"
},
{
"description": "This args are going to be injected to the KNeighborsClassifier.fit function directly",
"mandatory": true,
"type": "application",
"defaultValue": "{\"n_neighbors\":3}",
"key": "direct_args_to_sklearn_function",
"valueType": "STRING"
}
]
}
Ex. 8: Generic Assets
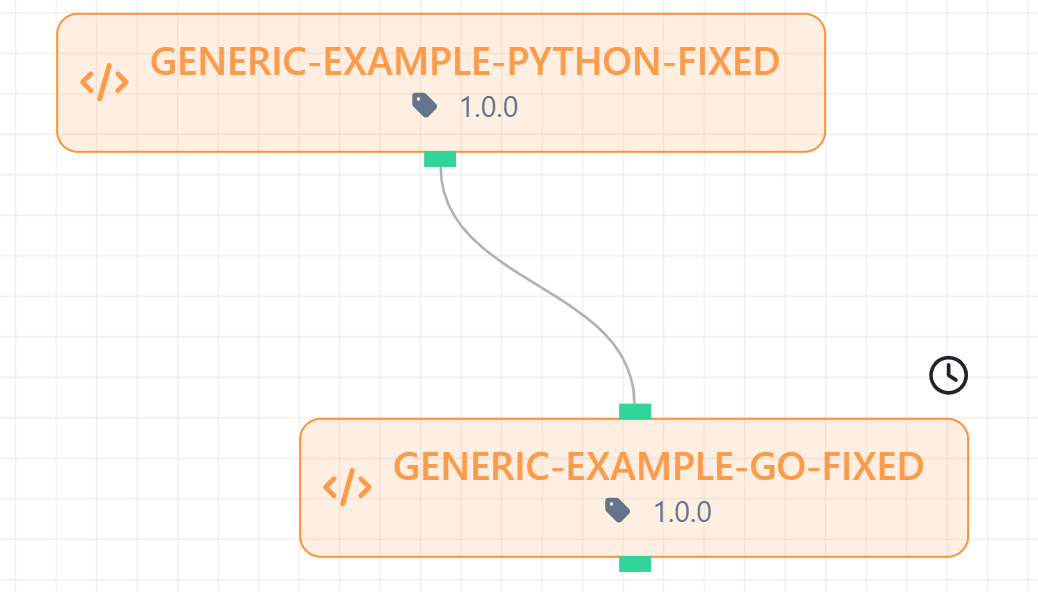
Core Program Code
package main
import (
"encoding/csv"
"fmt"
"os"
"path/filepath"
)
func appendHelloWorld(inputDir, outputDir string) {
// Find CSV files in the input directory
files, err := filepath.Glob(filepath.Join(inputDir, "*.csv"))
if err != nil {
fmt.Println("Error searching for files:", err)
return
}
if len(files) == 0 {
fmt.Println("No CSV files found in the input directory")
return
}
// Use the first found file
inputFile := files[0]
outputFile := filepath.Join(outputDir, "output.csv")
// Open the input file
file, err := os.Open(inputFile)
if err != nil {
fmt.Println("Error opening the file:", err)
return
}
defer file.Close()
reader := csv.NewReader(file)
rows, err := reader.ReadAll()
if err != nil {
fmt.Println("Error reading the file:", err)
return
}
// Add a new row with "hello world"
rows = append(rows, []string{"hello world"})
// Create the output directory if it does not exist
if err := os.MkdirAll(outputDir, os.ModePerm); err != nil {
fmt.Println("Error creating the output directory:", err)
return
}
// Write the modified CSV file
outFile, err := os.Create(outputFile)
if err != nil {
fmt.Println("Error creating the output file:", err)
return
}
defer outFile.Close()
writer := csv.NewWriter(outFile)
err = writer.WriteAll(rows)
if err != nil {
fmt.Println("Error writing the CSV file:", err)
return
}
fmt.Println("File saved:", outputFile)
}
func main() {
inputDir := "/inputs"
outputDir := "/outputs"
appendHelloWorld(inputDir, outputDir)
}
Metamodel
{
"name": "generic-go-ex1",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"description": "",
"mode": "BATCH",
"properties": [
{
"defaultValue": "{\"inputs\": [{\"name\": \"input-data\", \"path\": \"/inputs\", \"type\": \"dataset\",\"description\": \"my description\"}], \"outputs\": [{\"name\": \"output-data\", \"path\": \"/outputs\", \"type\": \"dataset\",\"description\": \"my description\"}]}",
"description": "",
"externalized": false,
"extra": null,
"invisible": true,
"key": "assets",
"mandatory": true,
"type": "application",
"uri": null,
"value": null,
"valueType": "JSON"
}
],
"ref": null,
"statusModel": null,
"tags": [],
"url": "docker://gitlab.alidalab.it:5000/alida/analytics2/example-go-1:latest"
}
Ex. 9: Spark - Python
Below is an example of a pyspark application that reads an input dataset, produces a model as output, and shares Spark driver logs through application media.
First let's look at the client image.
Dockerfile:
FROM apache/spark:4.0.1
USER root
# Install yq
RUN wget https://github.com/mikefarah/yq/releases/download/v4.45.1/yq_linux_amd64 -O /usr/local/bin/yq && \
chmod +x /usr/local/bin/yq
# Install jq
RUN apt-get update && apt-get install -y jq
USER spark
COPY entrypoint.sh .
ENTRYPOINT ["/bin/sh", "entrypoint.sh"]
#!/bin/bash
# Default variable (overwrite before script with export)
SPARK_MASTER="${SPARK_MASTER:-local[*]}"
SPARK_NAMESPACE="${NAMESPACE:-alida}"
SPARK_DEPLOY_MODE="${SPARK_DEPLOY_MODE:-client}"
SPARK_APP_NAME="${SPARK_APP_NAME:-sparkapp}"
SPARK_IMAGE="${SPARK_IMAGE:-dockerhub.alidalab.it/alida/restricted/services/spark-kmeans-example:1.0.1}"
SPARK_DRIVER_MEMORY="${SPARK_DRIVER_MEMORY:-4g}"
SPARK_DRIVER_CORES="${SPARK_DRIVER_CORES:-2}"
SPARK_EXECUTOR_MEMORY="${SPARK_EXECUTOR_MEMORY:-4g}"
SPARK_EXECUTOR_CORES="${SPARK_EXECUTOR_CORES:-2}"
SPARK_PULLSECRETS="${SPARK_PULLSECRETS:-alida-regcred}"
SEED="${SEED:-1}"
TARGET="${TARGET:-$(cat <<'EOF'
{
"affinity":{
"nodeAffinity":{
"requiredDuringSchedulingIgnoredDuringExecution":{
"nodeSelectorTerms":[
{
"matchExpressions":[
{
"key":"kubernetes.io/role",
"operator":"In",
"values":[
"opt-worker"
]
}
]
}
]
}
}
},
"tolerations":[
{
"effect":"NoSchedule",
"key":"opt-worker",
"operator":"Equal",
"value":"true"
},
{
"effect":"NoExecute",
"key":"opt-worker",
"operator":"Equal",
"value":"true"
}
]
}
EOF
)}"
# Extract affinity and tolerations into env vars
AFFINITY=$(echo "$TARGET" | jq -c '.affinity')
TOLERATIONS=$(echo "$TARGET" | jq -c '.tolerations')
echo "MAKING POD YAML DESCRIPTOR FROM TARGET ENV..."
# Convert JSON to YAML using yq
TOLERATIONS_YAML=$(echo "$TOLERATIONS" | yq eval -P -)
AFFINITY_YAML=$(echo "$AFFINITY" | yq eval -P -)
# Output to pod-template.yaml
cat <<EOF > pod-template.yaml
apiVersion: v1
kind: Pod
spec:
tolerations:
$(echo "$TOLERATIONS_YAML" | sed 's/^/ /')
affinity:
$(echo "$AFFINITY_YAML" | sed 's/^/ /')
EOF
echo "SUBMITTING SPARK APPLICATION..."
OUTPUT="$(/opt/spark/bin/spark-submit \
--master k8s://kubernetes.default.svc \
--deploy-mode cluster \
--name "${SPARK_APP_NAME}" \
--conf spark.kubernetes.namespace="${SPARK_NAMESPACE}" \
--conf spark.kubernetes.container.image=dockerhub.alidalab.it/alida/restricted/services/spark-kmeans-example:1.0.0 \
--conf spark.kubernetes.driver.limit.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.kubernetes.driver.limits.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.kubernetes.driver.request.cores="${SPARK_DRIVER_CORES}" \
--conf spark.kubernetes.executor.limit.memory="${SPARK_EXECUTOR_MEMORY}" \
--conf spark.kubernetes.executor.limits.memory="${SPARK_EXECUTOR_MEMORY}" \
--conf spark.kubernetes.executor.request.cores="${SPARK_EXECUTOR_CORES}" \
--conf spark.kubernetes.driver.podTemplateFile=pod-template.yaml \
--conf spark.kubernetes.executor.podTemplateFile=pod-template.yaml \
--conf spark.kubernetes.container.image.pullSecrets="${SPARK_PULLSECRETS}" \
--conf spark.kubernetes.driverEnv.EXECUTION_ID="${EXECUTION_ID}" \
--conf spark.kubernetes.driverEnv.HASH_TOKEN="${HASH_TOKEN}" \
--conf spark.kubernetes.driverEnv.SERVICE_ID="${SERVICE_ID}" \
--conf spark.kubernetes.container.image.pullPolicy=Always \
--conf spark.driver.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=argo-workflow \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.serializer=org.apache.spark.serializer.JavaSerializer \
--conf spark.hadoop.fs.s3a.connection.timeout=60000 \
--conf spark.hadoop.fs.s3a.connection.establish.timeout=5000 \
--conf spark.hadoop.fs.s3a.attempts.maximum=10 \
--conf spark.hadoop.fs.s3a.paging.maximum=1000 \
--conf spark.hadoop.fs.s3a.connection.maximum=200 \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider \
--conf spark.hadoop.fs.s3a.threads.keepalivetime=60000 \
--conf spark.hadoop.fs.s3a.connection.ttl=300000 \
--conf spark.hadoop.fs.s3a.multipart.purge.age=86400000 \
--conf spark.hadoop.fs.s3a.assumed.role.session.duration=1800000 \
--conf spark.driver.userClassPathFirst=true \
--conf spark.executor.userClassPathFirst=true \
--conf spark.driver.log.localDir=/tmp \
--conf spark.driver.extraJavaOptions="-Ddriver.log.dir=/tmp -Dlog4j2.configurationFile=/opt/spark/conf/log4j2.properties" \
local:///app/src/main/main.py $@ 2>&1)"
echo "$OUTPUT"
# Extract the driver exit code from logs
DRIVER_EXIT_CODE=$(echo "$OUTPUT" | grep -oP '(?<=exit code: )\d+' | head -1)
DRIVER_POD=$(echo "$OUTPUT" | grep -oP '(?<=pod name: )\S+' | head -1)
# If DRIVER_EXIT_CODE is empty, fallback to 1
if [ -z "$DRIVER_EXIT_CODE" ]; then
echo "Empty exit code, fallback to 1"
DRIVER_EXIT_CODE=1
fi
# Log and exit if driver exit code != 0
if [ "$DRIVER_EXIT_CODE" -ne 0 ]; then
echo "ERROR: $DRIVER_POD failed with exit code: $DRIVER_EXIT_CODE"
fi
echo "$DRIVER_POD terminated with exit code: $DRIVER_EXIT_CODE"
exit $DRIVER_EXIT_CODE
{
"name": "spark-kmeans-example-error",
"version": "1.0.0",
"accessLevel": "PUBLIC",
"description": "spark-kmeans-example-submit",
"mode": "BATCH",
"properties": [
{
"description": "Your input dataset",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "input-dataset",
"valueType": "STRING",
"invisible": true
},
{
"description": "Your output model",
"mandatory": true,
"type": "application",
"defaultValue": null,
"key": "output-model",
"valueType": "STRING",
"invisible": true
},
{
"dataset": null,
"defaultValue": "ANY",
"description": "Selected columns from table",
"inputData": false,
"invisible": true,
"key": "input-columns",
"mandatory": true,
"model": null,
"obfuscated": false,
"outputData": false,
"type": "application",
"value": null,
"valueType": "STRING"
},
{
"dataset": null,
"defaultValue": "3",
"description": "Number of clusters for KMeans.",
"extra": null,
"inputData": false,
"invisible": false,
"key": "n_clusters",
"mandatory": false,
"model": null,
"obfuscated": false,
"outputData": false,
"type": "application",
"value": null,
"valueType": "INT"
},
{
"defaultValue": "1",
"description": "SEED",
"invisible": false,
"key": "SEED",
"mandatory": false,
"obfuscated": false,
"type": "static",
"valueType": "STRING"
}
],
"url": "docker://dockerhub.alidalab.it/alida/restricted/services/spark-kmeans-example-submit-err:1.0.0"
}
Below is the application.
Dockerfile
FROM apache/spark:4.0.1
USER root
# Install Python 3 and pip
RUN apt-get update && \
apt-get install -y python3 python3-pip python3-dev && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
COPY ./requirements.txt .
RUN pip install -r requirements.txt
# install dependencies to read/write on S3-compatible
ADD https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.3.6/hadoop-aws-3.3.6.jar /opt/spark/jars/hadoop-aws-3.3.6.jar
ADD https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.12.406/aws-java-sdk-bundle-1.12.406.jar /opt/spark/jars/aws-java-sdk-bundle-1.12.406.jar
RUN chown -R spark:spark /opt/spark/jars
USER spark
COPY src/ /app/src/
# Copy custom log4j2 config
COPY log4j2.properties /opt/spark/conf/log4j2.properties
log4j2.properties
status = error
name = PropertiesConfig
# File appender (all logs go here)
appender.file.type = File
appender.file.name = FILE
appender.file.fileName = /path/to/your/logfile.log
appender.file.layout.type = PatternLayout
appender.file.layout.pattern = %d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%t] %c{1} - %msg%n
appender.file.immediateFlush = true
appender.file.append = true # ensure append mode
# Root logger
rootLogger.level = INFO
rootLogger.appenderRef.file.ref = FILE
import argparse
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0', ''):
return False
parser = argparse.ArgumentParser()
parser.add_argument('--input-dataset', dest='input_dataset', type=str, required=True)
parser.add_argument('--input-dataset.minio_bucket', dest='input_dataset_minio_bucket', type=str, required=True)
parser.add_argument('--input-dataset.minIO_URL', dest='input_dataset_minio_url', type=str, required=True)
parser.add_argument('--input-dataset.minIO_ACCESS_KEY', dest='input_dataset_access_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_SECRET_KEY', dest='input_dataset_secret_key', type=str, required=True)
parser.add_argument('--input-dataset.minIO_REGION', dest='input_dataset_region_name', type=str, required=True)
parser.add_argument('--input-dataset.use_ssl', dest='input_dataset_use_ssl', type=str2bool, required=True)
parser.add_argument('--output-model', dest='output_model', type=str, required=True)
parser.add_argument('--output-model.minio_bucket', dest='output_model_minio_bucket', type=str, required=True)
parser.add_argument('--output-model.minIO_URL', dest='output_model_minio_url', type=str, required=True)
parser.add_argument('--output-model.minIO_ACCESS_KEY', dest='output_model_access_key', type=str, required=True)
parser.add_argument('--output-model.minIO_SECRET_KEY', dest='output_model_secret_key', type=str, required=True)
parser.add_argument('--output-model.minIO_REGION', dest='output_model_region_name', type=str, required=True)
parser.add_argument('--output-model.use_ssl', dest='output_model_use_ssl', type=str2bool, required=True)
parser.add_argument("--n_clusters", help="Number of clusters for KMeans." ,type=int, default=5)
parser.add_argument("--max_iterations", help="Number of clusters for KMeans." ,type=int, default=5)
parser.add_argument('--input-columns', dest='input_columns', type=str, required=False)
parser.add_argument('--go_manager.brokers', dest='go_manager_brokers', type=str, required=True)
parser.add_argument('--go_manager.topic', dest='go_manager_topic', type=str, required=True)
parser.add_argument('--go_manager.base_path', dest='go_minio_path', type=str, required=True)
parser.add_argument('--go_manager.minio_bucket', dest='go_minio_bucket', type=str, required=True)
parser.add_argument('--go_manager.minIO_URL', dest='go_minio_url', type=str, required=True)
parser.add_argument('--go_manager.minIO_ACCESS_KEY', dest='go_access_key', type=str, required=True)
parser.add_argument('--go_manager.minIO_SECRET_KEY', dest='go_secret_key', type=str, required=True)
parser.add_argument('--go_manager.minIO_REGION', dest='go_manager_region_name', type=str, required=True)
parser.add_argument('--go_manager.use_ssl', dest='go_use_ssl', type=str2bool, required=True)
args, unknown = parser.parse_known_args()
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
from utils import send_application_media
from arguments import args
import os
import sys
import atexit
import traceback
log_local_dir = os.environ.get("DRIVER_LOG_DIR", "/tmp")
log_file_path = f"{log_local_dir}/driver.log"
log_file = open(log_file_path, "a") # append mode
sys.stdout = log_file
sys.stderr = log_file
print("This Python print will also go to the log file.")
def run_kmeans_example(k: int = 3,
max_iter: int = 20,
init_mode: str = "k-means||"):
"""
Runs KMeans clustering on a dataset.
Args:
input_path: path to data (could be CSV, Parquet, libsvm etc.)
k: number of clusters
max_iter: maximum number of iterations
tol: convergence tolerance
init_mode: initialization mode ("random" or "k-means||")
seed: random seed
"""
# Create Spark session (Spark 4.0.0)
spark = SparkSession.builder \
.appName("KMeansExample_Spark_4_0_0") \
.config("spark.hadoop.fs.s3a.endpoint", args.input_dataset_minio_url) \
.config("spark.hadoop.fs.s3a.access.key", args.input_dataset_access_key) \
.config("spark.hadoop.fs.s3a.secret.key", args.input_dataset_secret_key) \
.config("spark.hadoop.fs.s3a.connection.ssl.enabled", args.input_dataset_use_ssl) \
.getOrCreate()
sc = spark.sparkContext
df = spark.read.option("header", "true").option("inferSchema", "true").csv(f"s3a://{args.input_dataset_minio_bucket}/{args.input_dataset}")
#Suppose you know which columns are numeric features
feature_cols = [c for c, t in df.dtypes if t in ("double", "float", "int", "long")]
#Remove columns you don't want, e.g. label or id
feature_cols = [c for c in feature_cols if c not in ("CustomerID")]
# Assemble into feature vector
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_features = assembler.transform(df).select("features")
# Instantiate KMeans
kmeans = KMeans(
k=k,
initMode=init_mode,
maxIter=max_iter
)
# Fit the model
model = kmeans.fit(df_features)
# Get cluster centers
centers = model.clusterCenters()
print(f"Cluster Centers: {centers}")
# Make predictions
predictions = model.transform(df_features)
# Evaluate clustering (silhouette score)
evaluator = ClusteringEvaluator(metricName="silhouette", distanceMeasure="squaredEuclidean", featuresCol="features", predictionCol="prediction")
silhouette = evaluator.evaluate(predictions)
print(f"Silhouette with squared euclidean distance = {silhouette}")
# Summary: get sizes etc
summary = model.summary
print(f"Cluster sizes -> {summary.clusterSizes}")
print(f"Training cost (sum of squared distances): {summary.trainingCost}")
print(f"Number of iterations until convergence: {summary.numIter}")
print(f"Saving model to Minio")
model.write().overwrite().save(f"s3a://{args.output_model_minio_bucket}/{args.output_model}/kmeans-model-pyspark")
spark.stop()
def save_log_to_minio():
try:
send_application_media("/tmp/driver.log", "driver.log", "file", args)
except Exception:
print ("Failed to upload logs to application media")
traceback.print_exc()
if __name__ == "__main__":
atexit.register(save_log_to_minio)
print(f"START SPARK JOB - SERVICE {os.environ.get('SERVICE_ID', 'SERVICE_ID')}")
run_kmeans_example(k=args.n_clusters, max_iter=args.max_iterations, init_mode="k-means||")
print(f"END SPARK JOB - SERVICE {os.environ.get('SERVICE_ID', 'SERVICE_ID')}")
import json
import os
import uuid
from datetime import datetime
from kafka import KafkaProducer
from minio import Minio
def _init_producer_kafka(args):
if not hasattr(_init_producer_kafka, "_producer"):
kafka_brokers = args.go_manager_brokers.split(",")
_init_producer_kafka._producer = KafkaProducer(
bootstrap_servers=kafka_brokers
)
return _init_producer_kafka._producer
def upload_file_to_minio(minio_url, access_key, secret_key,region, bucket_name, object_name, local_file_path, secure=False):
# Initialize the MinIO client
address = minio_url.replace("http://", "").replace("https://", "")
client = Minio(address, access_key=access_key, secret_key=secret_key,region=region, secure=secure)
# Upload the file
client.fput_object(bucket_name, object_name, local_file_path)
def prepare_metadata_json(name, messageType):
result = {
"name": name,
"key": name.lower().replace(" ", "-"),
"uuid": str(uuid.uuid4()),
"messageType": messageType,
"created": str(datetime.now()),
"modified": str(datetime.now())
}
if "SERVICE_ID" in os.environ:
result['serviceId'] = os.environ.get('SERVICE_ID')
if "EXECUTION_ID" in os.environ:
result['executionId'] = os.environ.get('EXECUTION_ID')
if "HASH_TOKEN" in os.environ:
result['hashToken'] = os.environ.get('HASH_TOKEN')
return result
def send_message(data, args):
producer = _init_producer_kafka(args)
producer.send(args.go_manager_topic, json.dumps(data).encode('utf-8'))
producer.flush()
def prepare_file_metadata(name, messageType, path, extension, filename, **kwargs):
metadata = prepare_metadata_json(name=name, messageType=messageType, **kwargs)
metadata['path'] = path
metadata['extension'] = extension
if messageType == "picture":
metadata['filename'] = filename
return metadata
def send_application_media(file_to_send, file_name, file_type, args, **kwargs):
folder = args.go_minio_path
if folder[-1] != "/":
folder = folder + "/"
metadata = prepare_file_metadata(name=os.path.basename(file_to_send).split('.')[0], messageType=file_type, path=folder + file_name,
extension=os.path.basename(file_to_send).split('.')[-1], filename=file_name, **kwargs)
upload_file_to_minio(args.go_minio_url, args.go_access_key, args.go_secret_key,args.go_region_name, args.go_minio_bucket, folder + file_name, file_to_send, secure=args.go_use_ssl)
print(f"[MEDIA] type={file_type} local={file_to_send} remote_object={args.go_minio_url} uploadto={args.go_minio_path + file_name}")
send_message(metadata, args)
def send_log(name, value, value_type, args, **kwargs):
message_to_sent = prepare_metadata_json(name, "log", **kwargs)
message_to_sent['value'] = value
message_to_sent['valueType'] = value_type
send_message(message_to_sent, args)
Ex. 10: Spark - Java
Below is an example of a Spark application in Java that reads an input dataset, produces a model as output, and shares Spark driver logs through application media.
First let's look at the client image.
The Dockerfile is standard; it installs jq and yq tools to manipulate JSON and YAML to prepare the pod template.
FROM apache/spark:4.0.1
USER root
# Install yq
RUN wget https://github.com/mikefarah/yq/releases/download/v4.45.1/yq_linux_amd64 -O /usr/local/bin/yq && \
chmod +x /usr/local/bin/yq
# Install jq
RUN apt-get update && apt-get install -y jq
USER spark
COPY entrypoint.sh .
ENTRYPOINT ["/bin/sh", "entrypoint.sh"]
#!/bin/bash
set -e
# Variabili con default (sovrascrivibili con export prima dello script)
SPARK_MASTER="${SPARK_MASTER:-local[*]}"
SPARK_NAMESPACE="${NAMESPACE:-alida}"
SPARK_DEPLOY_MODE="${SPARK_DEPLOY_MODE:-client}"
SPARK_APP_NAME="${SPARK_APP_NAME:-sparkapp}"
SPARK_IMAGE="${SPARK_IMAGE:-dockerhub.alidalab.it/alida/restricted/services/spark-kmeans-java-example:1.0.0}"
SPARK_DRIVER_MEMORY="${SPARK_DRIVER_MEMORY:-4g}"
SPARK_DRIVER_CORES="${SPARK_DRIVER_CORES:-1}"
SPARK_EXECUTOR_MEMORY="${SPARK_EXECUTOR_MEMORY:-4g}"
SPARK_EXECUTOR_CORES="${SPARK_EXECUTOR_CORES:-1}"
SPARK_PULLSECRETS="${SPARK_PULLSECRETS:-alida-regcred}"
SEED="${SEED:-1}"
TARGET="${TARGET:-$(cat <<'EOF'
{
"affinity":{
"nodeAffinity":{
"requiredDuringSchedulingIgnoredDuringExecution":{
"nodeSelectorTerms":[
{
"matchExpressions":[
{
"key":"kubernetes.io/role",
"operator":"In",
"values":[
"opt-worker"
]
}
]
}
]
}
}
},
"tolerations":[
{
"effect":"NoSchedule",
"key":"opt-worker",
"operator":"Equal",
"value":"true"
},
{
"effect":"NoExecute",
"key":"opt-worker",
"operator":"Equal",
"value":"true"
}
]
}
EOF
)}"
# Extract affinity and tolerations into env vars
AFFINITY=$(echo "$TARGET" | jq -c '.affinity')
TOLERATIONS=$(echo "$TARGET" | jq -c '.tolerations')
echo "MAKING POD YAML DESCRIPTOR FROM TARGET ENV..."
# Convert JSON to YAML using yq
TOLERATIONS_YAML=$(echo "$TOLERATIONS" | yq eval -P -)
AFFINITY_YAML=$(echo "$AFFINITY" | yq eval -P -)
# Output to pod-template.yaml
cat <<EOF > pod-template.yaml
apiVersion: v1
kind: Pod
spec:
tolerations:
$(echo "$TOLERATIONS_YAML" | sed 's/^/ /')
affinity:
$(echo "$AFFINITY_YAML" | sed 's/^/ /')
EOF
echo "SUBMITTING SPARK APPLICATION..."
OUTPUT="$(/opt/spark/bin/spark-submit \
--master k8s://kubernetes.default.svc \
--deploy-mode cluster \
--name "${SPARK_APP_NAME}" \
--class it.eng.spark.Kmeans \
--conf spark.kubernetes.namespace="${SPARK_NAMESPACE}" \
--conf spark.kubernetes.container.image=dockerhub.alidalab.it/alida/restricted/services/spark-kmeans-java-example:1.0.0 \
--conf spark.kubernetes.driver.limit.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.kubernetes.driver.limits.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.kubernetes.driver.request.cores="${SPARK_DRIVER_CORES}" \
--conf spark.kubernetes.executor.limit.memory="${SPARK_EXECUTOR_MEMORY}" \
--conf spark.kubernetes.executor.limits.memory="${SPARK_EXECUTOR_MEMORY}" \
--conf spark.kubernetes.executor.request.cores="${SPARK_EXECUTOR_CORES}" \
--conf spark.kubernetes.driver.podTemplateFile=pod-template.yaml \
--conf spark.kubernetes.executor.podTemplateFile=pod-template.yaml \
--conf spark.kubernetes.driverEnv.SEED="${SEED}" \
--conf spark.kubernetes.executorEnv.SEED="${SEED}" \
--conf spark.kubernetes.container.image.pullSecrets="${SPARK_PULLSECRETS}" \
--conf spark.kubernetes.container.image.pullPolicy=Always \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=argo-workflow \
--conf spark.driver.memory="${SPARK_DRIVER_MEMORY}" \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.serializer=org.apache.spark.serializer.JavaSerializer \
--conf spark.hadoop.fs.s3a.connection.timeout=60000 \
--conf spark.hadoop.fs.s3a.connection.establish.timeout=5000 \
--conf spark.hadoop.fs.s3a.attempts.maximum=10 \
--conf spark.hadoop.fs.s3a.paging.maximum=1000 \
--conf spark.hadoop.fs.s3a.connection.maximum=200 \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider \
--conf spark.hadoop.fs.s3a.threads.keepalivetime=60000 \
--conf spark.hadoop.fs.s3a.connection.ttl=300000 \
--conf spark.hadoop.fs.s3a.multipart.purge.age=86400000 \
--conf spark.hadoop.fs.s3a.assumed.role.session.duration=1800000 \
--conf spark.kubernetes.driverEnv.EXECUTION_ID="${EXECUTION_ID}" \
--conf spark.kubernetes.driverEnv.HASH_TOKEN="${HASH_TOKEN}" \
--conf spark.kubernetes.driverEnv.SERVICE_ID="${SERVICE_ID}" \
--conf spark.driver.userClassPathFirst=true \
--conf spark.executor.userClassPathFirst=true \
--conf spark.driver.log.localDir=/tmp \
--conf spark.driver.extraJavaOptions="-Ddriver.log.dir=/tmp -Dlog4j.configurationFile=/tmp/log4j2.properties" \
--conf spark.executor.extraJavaOptions="-Dlog4j2.configurationFile=/tmp/log4j2.xml -Ddriver.log.dir=/tmp" \
local:///tmp/kmeans-example-1.0.jar $@ 2>&1)"
echo "$OUTPUT"
# Extract the driver exit code from logs
DRIVER_EXIT_CODE=$(echo "$OUTPUT" | grep -oP '(?<=exit code: )\d+' | head -1)
DRIVER_POD=$(echo "$OUTPUT" | grep -oP '(?<=pod name: )\S+' | head -1)
# If DRIVER_EXIT_CODE is empty, fallback to 1
if [ -z "$DRIVER_EXIT_CODE" ]; then
echo "Empty exit code, fallback to 1"
DRIVER_EXIT_CODE=1
fi
# Log and exit if driver exit code != 0
if [ "$DRIVER_EXIT_CODE" -ne 0 ]; then
echo "ERROR: $DRIVER_POD failed with exit code: $DRIVER_EXIT_CODE"
fi
echo "$DRIVER_POD terminated with exit code: $DRIVER_EXIT_CODE"
exit $DRIVER_EXIT_CODE
Below is the application image. The Dockerfile loads the application JAR and the log4j2 configuration file.
Dockerfile
FROM apache/spark:4.0.1
COPY target/kmeans-example-1.0.jar /tmp/kmeans-example-1.0.jar
COPY log4j2.properties /tmp/log4j2.properties
log4j2.properties
status = error
# Console appender
appender.console.type = Console
appender.console.name = CONSOLE
appender.console.target = SYSTEM_OUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss} [%t] %-5p %c{1}: %m%n
# File appender
appender.file.type = File
appender.file.name = FILE
appender.file.fileName = /tmp/application.log
appender.file.append = true
appender.file.layout.type = PatternLayout
appender.file.layout.pattern = %d{yyyy-MM-dd HH:mm:ss} [%t] %-5p %c{1}: %m%n
# Root logger references both
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = CONSOLE
rootLogger.appenderRef.file.ref = FILE
logger.spark.name = org.apache.spark
logger.spark.level = INFO
logger.spark.additivity = false
logger.spark.appenderRef.file.ref = FILE
logger.spark.appenderRef.console.ref = CONSOLE
Below is the pom.xml. The shade plugin was used to create a fat JAR that includes the runtime dependencies. Note the provided scope for Spark-provided dependencies and the exclusions for unnecessary AWS modules.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>it.eng.spark</groupId>
<artifactId>kmeans-example</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<spark.version>4.0.1</spark.version>
<scala.binary.version>2.13</scala.binary.version>
<hadoop.version>3.4.1</hadoop.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- Spark MLlib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.1</version>
</dependency>
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.5.7</version>
<exclusions>
<exclusion>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-bundle</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>software.amazon.awssdk</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Maven Compiler Plugin -->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<source>17</source>
<target>17</target>
</configuration>
</plugin>
<!-- Maven Shade Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>true</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<!-- Exclude all useless AWS & SLF4J from the shaded JAR -->
<excludes>
<exclude>com/amazonaws/services/dynamodbv2/**</exclude>
<exclude>com/amazonaws/services/sqs/**</exclude>
<exclude>com/amazonaws/services/kinesis/**</exclude>
<exclude>org/slf4j/**</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<!-- Set Main-Class -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>it.eng.spark.Kmeans</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
package it.eng.spark;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.util.VersionInfo;
import org.apache.spark.SparkConf;
import org.apache.spark.ml.clustering.KMeans;
import org.apache.spark.ml.clustering.KMeansModel;
import org.apache.spark.ml.evaluation.ClusteringEvaluator;
import org.apache.spark.ml.feature.StringIndexer;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Kmeans {
private static final Logger logger = LoggerFactory.getLogger(Kmeans.class);
private static Map<String, String> convertToKeyValuePair(String[] args) {
HashMap<String, String> params = new HashMap<>();
for (String arg: args) {
if (arg.contains("=")) {
String[] splitFromEqual = arg.split("=");
String key = splitFromEqual[0].substring(2);
String value = splitFromEqual[1];
params.put(key, value);
}
}
return params;
}
private static void uploadLogs(Map<String, String> arguments) {
try {
logger.info("Sending logs to application media...");
Utils.sendApplicationMedia(System.getProperty("driver.log.dir")+"/driver.log", "driver.log", "file", arguments);
Utils.sendApplicationMedia(System.getProperty("driver.log.dir")+"/application.log", "application.log", "file", arguments);
logger.info("Sent logs to application media.");
}catch(Exception e) {
logger.error("Error uploading logs at exit.");
logger.error(e.getMessage(), e);
}
}
private static void executeJob(Map<String, String> arguments) throws IOException {
logger.info("START - KMEANS");
logger.info("Hadoop version in classpath: {}", VersionInfo.getVersion());
logger.info("SEED {}", System.getenv("SEED"));
SparkConf sparkConf = new SparkConf()
.set("spark.hadoop.fs.s3a.endpoint", arguments.get("input-dataset.minIO_URL"))
.set("spark.hadoop.fs.s3a.access.key", arguments.get("input-dataset.minIO_ACCESS_KEY"))
.set("spark.hadoop.fs.s3a.secret.key", arguments.get("input-dataset.minIO_SECRET_KEY"))
.set("spark.hadoop.fs.s3a.connection.ssl.enabled", arguments.get("input-dataset.use_ssl"));
SparkSession spark = SparkSession
.builder()
.appName("JavaKMeansExample")
.config(sparkConf)
.getOrCreate();
String bucketName = arguments.get("input-dataset.minio_bucket");
String folderPath = arguments.get("input-dataset");
Dataset<Row> dataset = spark
.read()
.format("csv")
.option("header","true")
.option("inferSchema", "true")
.csv("s3a://"+bucketName+"/"+folderPath)
;
dataset = dataset.select("sepal_length", "sepal_width", "petal_length", "petal_width", "variety");
logger.info("=== Sample of the input dataset ===");
dataset.show(10, false);
// Convert string label to numeric index (useful for cross-tab)
StringIndexer indexer = new StringIndexer()
.setInputCol("variety")
.setOutputCol("varietyIndex")
.setHandleInvalid("keep");
Dataset<Row> withIndex = indexer.fit(dataset).transform(dataset);
// Assemble features into a single vector column
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"sepal_length", "sepal_width", "petal_length", "petal_width"})
.setOutputCol("features");
Dataset<Row> withFeatures = assembler.transform(withIndex).select("features", "variety", "varietyIndex");
// Configure KMeans
KMeans kmeans = new KMeans()
.setK(Integer.parseInt(arguments.get("k")))
.setSeed(Long.parseLong(System.getenv("SEED")))
.setMaxIter(Integer.parseInt(arguments.get("maxIterations")))
.setFeaturesCol("features")
.setPredictionCol("prediction");
// Train model
KMeansModel model = kmeans.fit(withFeatures);
//Save model to minio
String modelBucket = arguments.get("output-model.minio_bucket");
String bucketPath = arguments.get("output-model");
String modelOutputPath = "s3a://"+modelBucket+"/"+bucketPath+"/kmeans-model";
model.write().overwrite().save(modelOutputPath);
logger.info("Model saved successfully to MinIO: " + modelOutputPath);
// Make predictions
Dataset<Row> predictions = model.transform(withFeatures);
// Show cluster centers
logger.info("=== Cluster Centers ===");
org.apache.spark.ml.linalg.Vector[] centers = model.clusterCenters();
for (int i = 0; i < centers.length; i++) {
logger.info("Center " + i + ": " + centers[i]);
}
// Evaluate clustering by silhouette score
ClusteringEvaluator evaluator = new ClusteringEvaluator()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setMetricName("silhouette");
double silhouette = evaluator.evaluate(predictions);
logger.info("Silhouette with squared euclidean distance = " + silhouette);
// Show counts per cluster
logger.info("=== Counts per cluster ===");
predictions.groupBy("prediction").count().show(false);
// Cross-tab between prediction and true variety
logger.info("=== Cross-tab (prediction vs variety) ===");
predictions.groupBy("prediction", "variety").count().orderBy("prediction").show(100, false);
spark.stop();
logger.info("END - KMEANS");
}
public static void main (String[] args) throws IOException {
Map<String, String> arguments = convertToKeyValuePair(args);
Runtime.getRuntime().addShutdownHook(new Thread(() -> uploadLogs(arguments)));
try {
executeJob(arguments);
}catch(Exception e) {
logger.error(e.getMessage(), e);
throw e;
}
}
}
package it.eng.spark;
import java.util.HashMap;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.minio.MinioClient;
import io.minio.UploadObjectArgs;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.File;
import java.time.LocalDateTime;
import java.util.Map;
import java.util.Properties;
import java.util.UUID;
public class Utils {
private static KafkaProducer<String, String> kafkaProducer;
private static final ObjectMapper mapper = new ObjectMapper();
public static HashMap<String, String> convertToKeyValuePair(Object[] args) {
HashMap<String, String> params = new HashMap<>();
for (Object argument: args) {
String arg = (String) argument;
if (arg.contains("=")) {
String[] splitFromEqual = arg.split("=");
String key = splitFromEqual[0].substring(2);
String value = splitFromEqual[1];
params.put(key, value);
}
}
return params;
}
private static KafkaProducer<String, String> initKafkaProducer(Map<String, String> args) {
if (kafkaProducer == null) {
Properties props = new Properties();
props.put("bootstrap.servers", args.get("go_manager.brokers"));
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProducer = new KafkaProducer<>(props);
}
return kafkaProducer;
}
public static void sendMessage(Map<String, Object> data, Map<String, String> args) throws Exception {
KafkaProducer<String, String> producer = initKafkaProducer(args);
String json = mapper.writeValueAsString(data);
producer.send(new ProducerRecord<>(args.get("go_manager.topic"), json));
producer.flush();
}
public static Map<String, Object> prepareFileMetadata(String name, String messageType, String path, String extension, String filename) {
Map<String, Object> metadata = prepareMetadataJson(name, messageType);
metadata.put("path", path);
metadata.put("extension", extension);
if ("picture".equals(messageType)) {
metadata.put("filename", filename);
}
return metadata;
}
public static Map<String, Object> prepareMetadataJson(String name, String messageType) {
Map<String, Object> result = new HashMap<>();
result.put("name", name);
result.put("key", name.toLowerCase().replace(" ", "-"));
result.put("uuid", UUID.randomUUID().toString());
result.put("messageType", messageType);
result.put("created", LocalDateTime.now().toString());
result.put("modified", LocalDateTime.now().toString());
if (System.getenv("SERVICE_ID") != null)
result.put("serviceId", System.getenv("SERVICE_ID"));
if (System.getenv("EXECUTION_ID") != null)
result.put("executionId", System.getenv("EXECUTION_ID"));
if (System.getenv("HASH_TOKEN") != null)
result.put("hashToken", System.getenv("HASH_TOKEN"));
return result;
}
public static void sendApplicationMedia(String fileToSend, String fileName, String fileType, Map<String, String> args) throws Exception {
String folder = args.get("go_manager.base_path").endsWith("/") ? args.get("go_manager.base_path") : args.get("go_manager.base_path") + "/";
String extension = new File(fileToSend).getName().replaceAll(".*\\.", "");
String objectName = folder + fileName;
String baseName = new File(fileToSend).getName().replace("." + extension, "");
Map<String, Object> metadata = prepareFileMetadata(baseName, fileType, objectName, extension, fileName);
uploadFileToMinio(args.get("go_manager.minIO_URL"), args.get("go_manager.minIO_ACCESS_KEY"), args.get("go_manager.minIO_SECRET_KEY"),args.get("go_manager.minio_region_name"), args.get("go_manager.minio_bucket"), objectName, fileToSend, Boolean.parseBoolean(args.get("go_manager.use_ssl")));
sendMessage(metadata, args);
}
public static void uploadFileToMinio(String minioUrl, String accessKey, String secretKey,
String bucketName, String objectName, String localFilePath, boolean secure) throws Exception {
String endpoint = secure ? "https://" : "http://";
MinioClient client = MinioClient.builder()
.endpoint(endpoint+minioUrl)
.credentials(accessKey, secretKey)
.build();
client.uploadObject(
UploadObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.filename(localFilePath)
.build()
);
}
}
Ex. 11: Service Exposure over the Network
Services can expose network ports. The URL where the service will be reachable is shown by the UI:
To expose a service on the network you must:
1. Specify the portsToExpose property inside the metamodel during service registration
2. Implement the HTTP endpoint inside the service using any framework of your choice
Python example with FastAPI + Uvicorn
from fastapi import FastAPI, Request
from arguments import args
app = FastAPI(
title="Test service",
description="This service is only for test purpose and return custom response"
)
@app.get("/")
def custom_response(request: Request):
raw = args.custom_response
if raw:
return raw
else:
return {
"status": "default"
}